Hello everyone,
I’m working on the XFS write support and have implemented the necessary structures like the metadata regarding the Free Space Block, Inode B+ tree, and AG Free list along with the Short form header. I had also tested them out in the xfs_shell. Should I now Submit a patch regarding all this? or Should I work more on it?
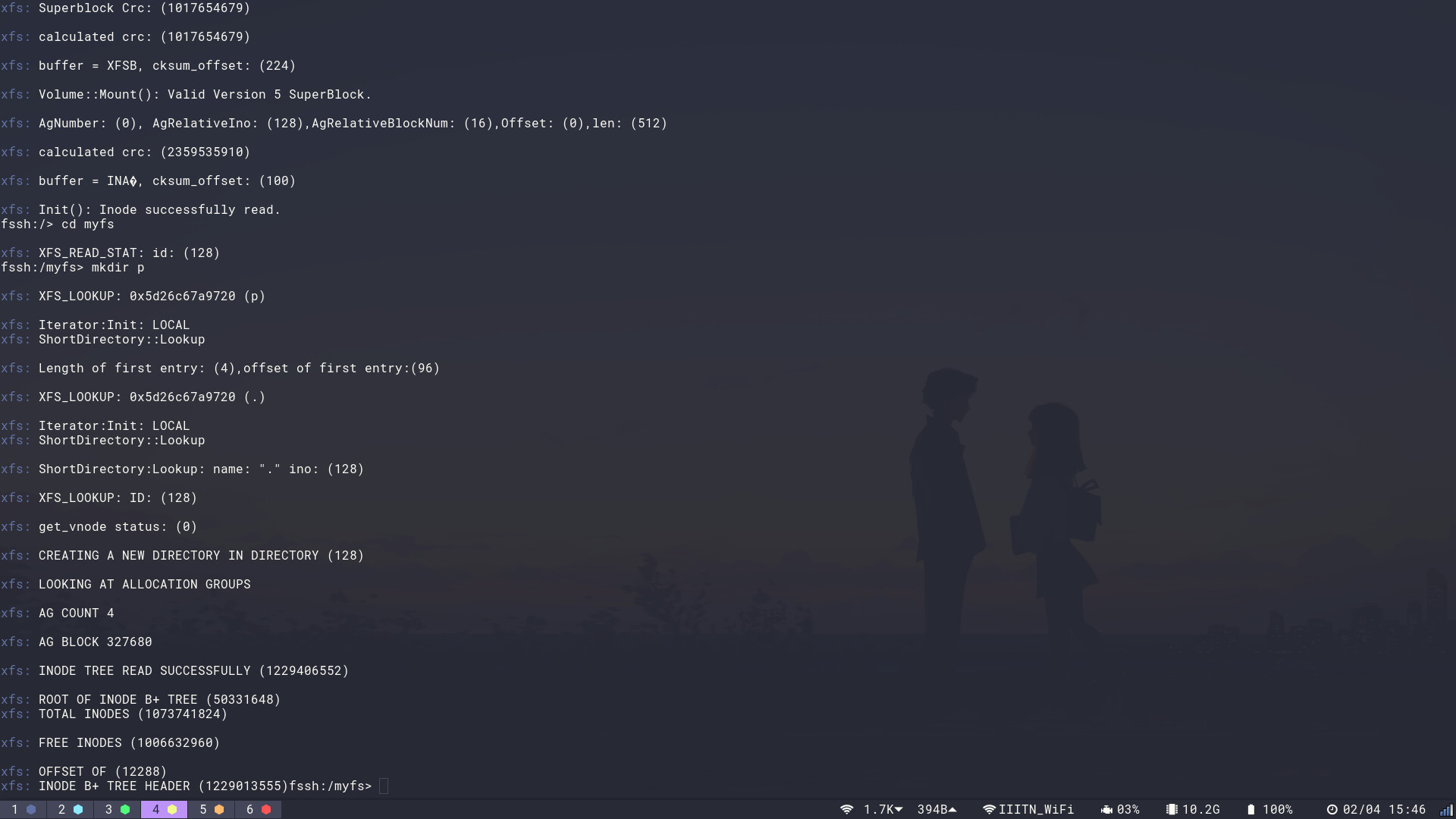
Here are some of the Images from my testing here I mainly focus on the Magic numbers to verify the Identity of the Data Blocks. Suggestions are welcome
I have tried to Check the CRC for this metadata structure regarding the Free Space per Allocation group there is only a single problem in the Function Valid_Crc as I have hard-coded the sector size. Should I pass the SuperBlock as an argument to the function? or there can be any other way.
this is the function it is woking fine with the CRC Check.
Yes, you need the sector size defined in sb_sectsize in the superblock. I think for now you can pass the sector size as an argument to the function, it will be easier to understand than passing the complete superblock.
Current Status: I’ve worked with the xfs_shell and the xfs Images on my Linux system for some previous days. During my work, I have got a fairly good hold of the On-Disk Format of the metadata Structures of FreeSpaces Inode Allocation and how The XFS organizes Data, and CRC Validation I have learned a lot about this Project, it’s getting more and more interesting.
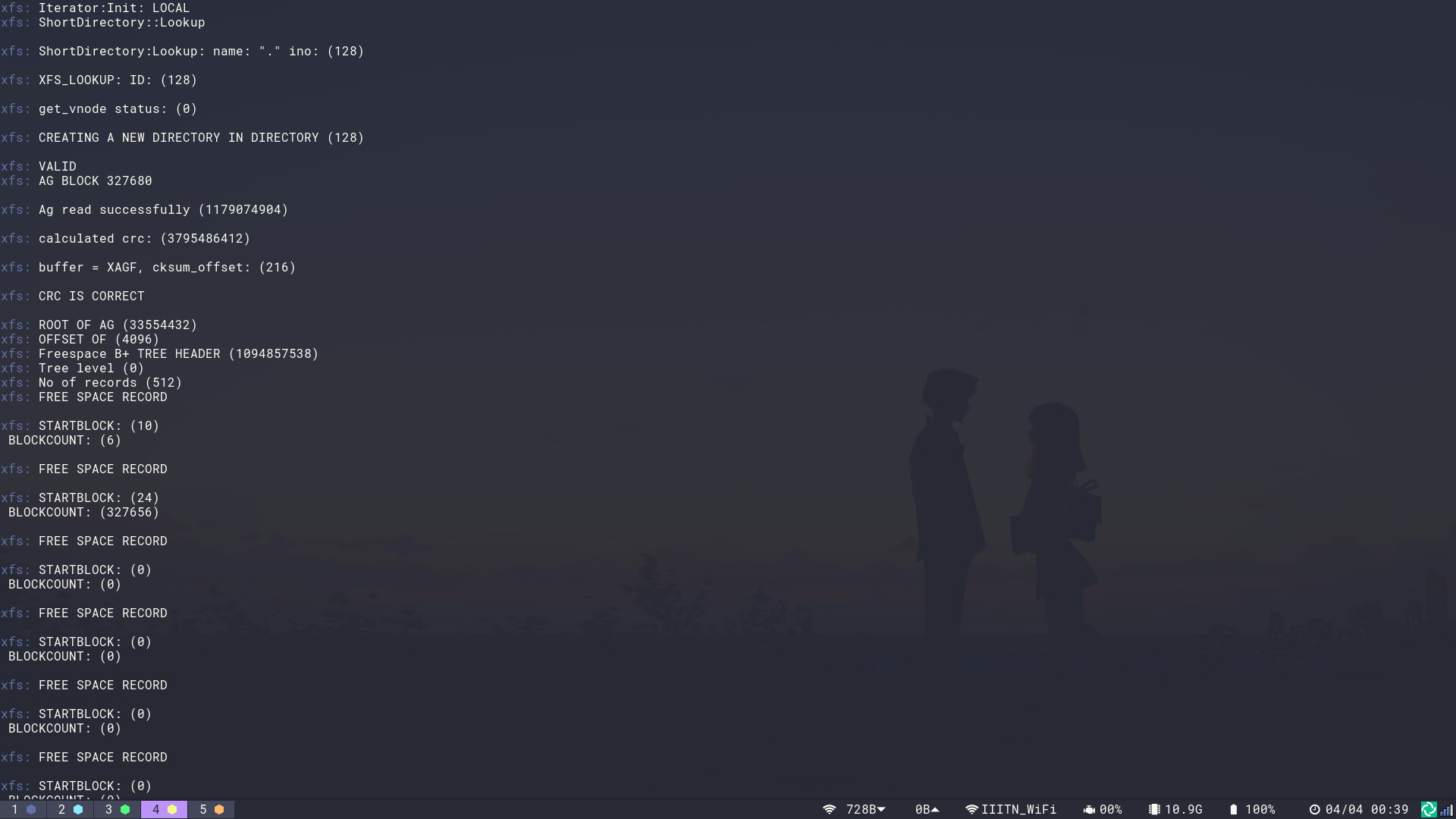
Approach: Instead of Implementing the Structures like the FreeSpace B+ trees, Inode trees. I’m thinking of Implementing the Read Support for these Structures and necessary Checks and Trying for Allocation of Space and Inodes from these structures so we can create directories in the XFS drives by this method, I’m thinking of some Dummy Allocation first, then optimize this for the rest of the FileSystem. Is this approach good? Suggestions are Welcome. Here are some of the screenshots from my work in the XFS shell.
There are multiple steps to creating a directory in a filesystem:
Finding some free space to store the new data
Reserve the space so that it is not marked free anymore (otherwise something else could allocate the same space and overwrite our data)
Write the new content to the allocated place
Register the newly allocated file or directory by adding it to its parent directory
All of this, of course, while ensuring filesystem consistency by using the filesystem journal as needed.
So, yes, all these steps need to be implemented one by one.
Also, when doing everything with direct disk access, it will be quite slow, since the data will be read from disk over and over again. It may be a good idea to set up caches. There is a work in progress change for it: https://review.haiku-os.org/c/haiku/+/5765 but it was never completed. Maybe it’s a goood idea to integrate it in your plan, since, the more changes you make, the harder it will be to reuse this existing work.
Currently, I’m working on the FreeSpace B+ trees. I want more than 1 level in this tree and to get a good version of internal nodes but unfortunately, the XFS driver can’t read 10K directories. There is some problem with the B+ tee lookup. Furthermore, I came across this discussion https://discuss.haiku-os.org/t/xfs-file-system-testing/12094/22?u=priyanshu this is from GSOC 2022 contributor @Mashijams highlighting the same problem. He did good work Tracing the root cause of the problem in the Searchandfillpath() function. I tried to look into that too and follow your suggestion on the process and Trace the value of path[ i ].type and it’s giving the correct result. The function is showing unusual behavior it’s working fine for some iterations.
for (int i = 0; i < MAX_TREE_DEPTH && level >= 0; i++, level--) {
uint64 requiredBlock = B_BENDIAN_TO_HOST_INT64(*ptrToNode);
TRACE("pathBlockno:(%d)\n", path[i].blockNumber);
TRACE("pathtype:(%d)\n", path[i].type);
TRACE("requiredBlock:(%" B_PRIu64 ")\n", requiredBlock);
if (path[i].blockNumber == requiredBlock) {
TRACE("here1");
// This block already has what we need
if (path[i].type == 2)
{
TRACE("here2");
break;
}
Here the for loop above breaks and no value outside the loop is updated we are just returning the status Still before coming outside the loop this gives a Segmentation fault. Do you have any suggestions for this?
B+Tree source code here is messy to say the least.
Lots of memory consumption and leaks are there.
When running in xfs_shell the memory required exceeds memory available which causes this weird problem of listing directories unknown numbers of directories.
If you are gonna run same image directly inside haiku, it could work but it will be very very slow again due to lots of disk reading and memory allocation.
Can you suggest something that can be done to resolve this? Implementation of Cache is going to take time and I still do not have much idea regarding this implementation can something be done to clean the B+ tree source code?
That’s why this kind of project is not yet done and instead turned into a GSoC project where you can spend several hundred hours on it.
If there are memory leaks, identify and fix them. This probably means deciding on a consistent allocation strategy (defining hwo is responsible for freeing the memory, and how the code keeps track of it) and possibly avoiding using hand-crafted management with new/delete, using, for exemple BReference (a reference counting system) or AutoDeleter (a C++ RAII based system to automatically release resources when a function is exited).
I have tried to work with cache and saw the suggestion in the discussion https://review.haiku-os.org/c/haiku/+/5765. Here you suggest replacing the read_pos call with the cache_get(); I have done the same and implemented the Cache_get_etc() for reading the direct offset in case of reading inodes. Now I want to replace the read_pos call in Inode::GetFromDisk where we fill the buffer. I have replaced read_pos with this but it’s giving segmentation faults can you suggest where I’m making a mistake or how to correctly replace them with Cache, Any references?
It’s hard to debug or review just 6 lines of code from a much bigger piece of software.
Please send your changes on Gerrit, so it can be reviewed in full.
Still here are some things to check:
That Cache is not null at that point and is pointing to a valid cache object
That offset * len does not go past the end of the block you got from the cache. If the offset or len is too large, you may be reading past the data that the cache can provide you?
Thank you for the Suggestion. Sorry for this silly mistake, I have resolved the error now I’m thinking of Changing the inode’s read_pos and then submitting a change regarding this and I still have to work with Cache_get_etc.
Hii all,
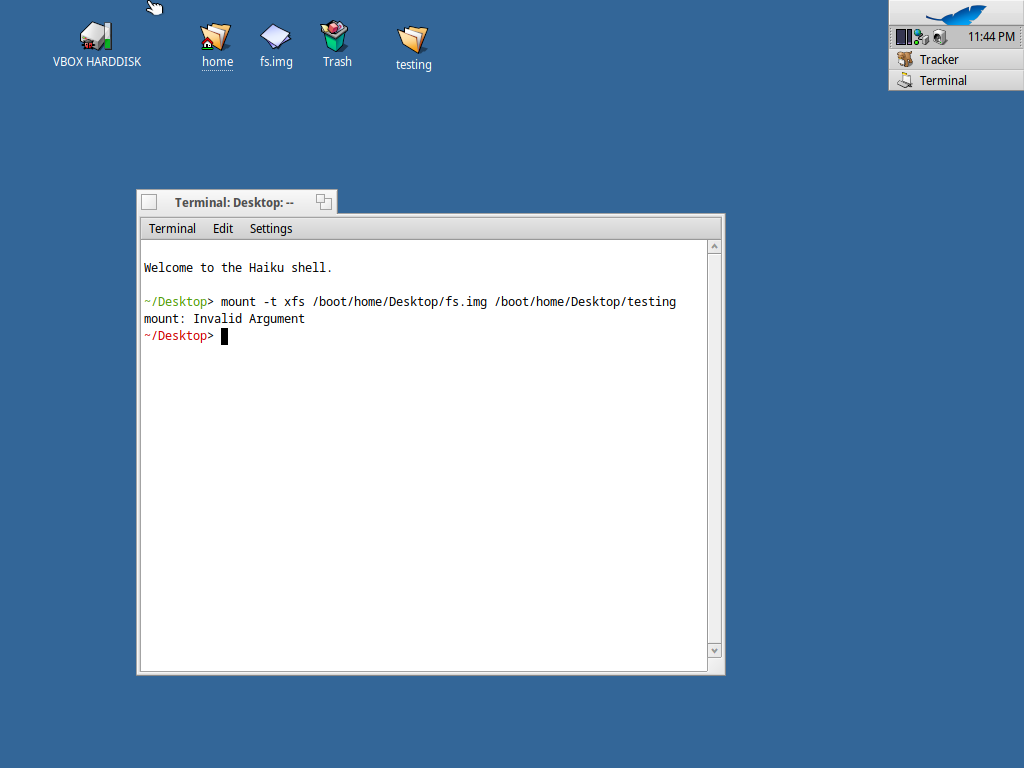
I have tried to implement Block Cache and they are working fine inside the xfs_shell now I want to test them inside the haiku itself. I have compiled haiku with the xfs in the image definition and created the image definition using :
dd if=/dev/zero of=fs.img bs=1 count=0 seek=5G
after this the /sbin/mkfs.xfs fs.img isn’t working and while trying to mount this image on the mounting point which is the testing folder, I’m getting this.
I’m not a developer, but seems your Haiku install is corrupted - the ladybird on the ‘VBOX HARDDISK’ indicades it-
Try checkfs -c /boot in Terminal - it may show the error
without -c switch the checkfs command attempt to fix your bfs partition.
I would do a reboot after that.
If it had not fixed, you need a new install of Haiku in the VirtualBox or if you thinked about it and you have a spare copy of your virtual drive … then you can make a copy about it onto the original one … overwritten.
It is useful to copy the virtual drive time-to-time – creating a “snapshot” about it manually as then you can restore a healthy status of your drive without too much struggle to keep the needed at your hands healthy and reliable.
Ah of course, the copy of the virtual drive (the file) should be donewhile the affected guest OS is shutted down, so the drive does not changing.