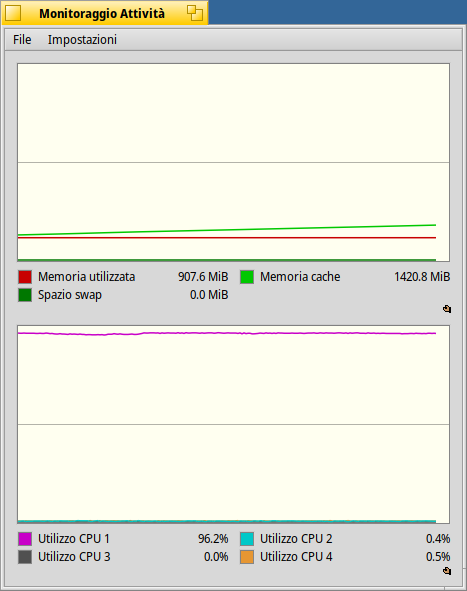
The scheduler tries to fulfill many constraints, for example, balance the load on the different CPU cores and caches. If you have 2 cores with hyperthreading, it is better to use just one thread of each core. But if you do so for a long time, that core will heat up more than the other, and so it will exit its “turbo boost” mode to not overheat. So it is a good idea to migrate to another core after a while, until the first one cools down.
So, if you hit a case like this, the threads will be moved from one core to another periodically.
There are also other things to take into account, for example, when a thread does a disk access, it is put on wait until the reply from the disk is received, and when it becomes ready again, it may be put on another idle CPU. Maybe there is now another task (even one with little CPU use) running on the CPU where it was initially. And it does not cost anything to put it on another idle CPU at that point.
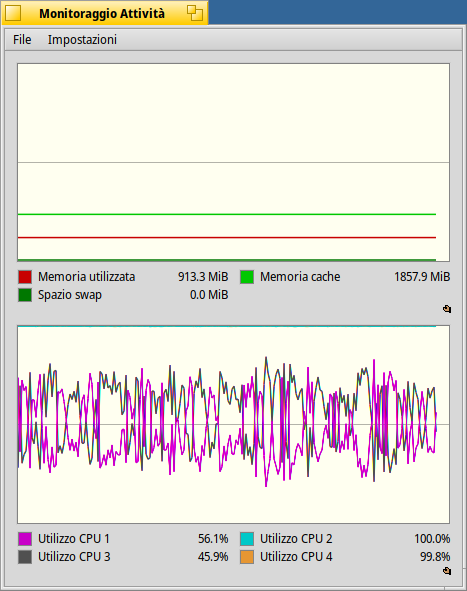
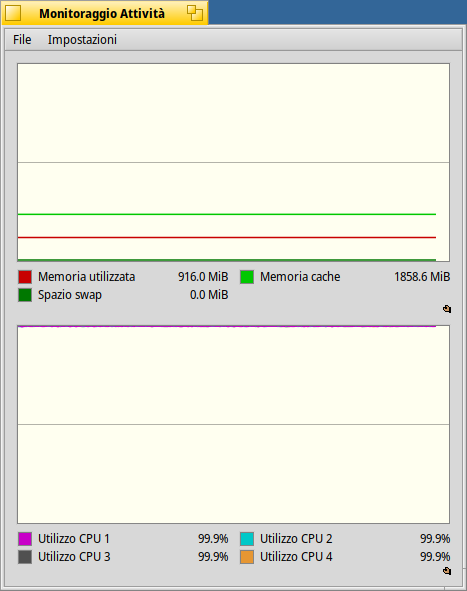
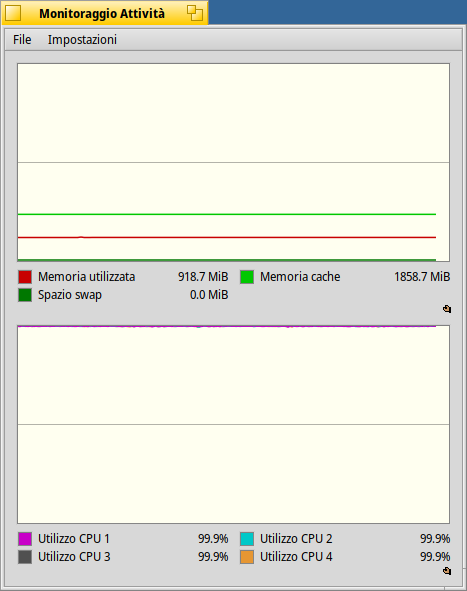
So, there is nothing in these graph that allows to say the scheduling is sub-optimal. If you really only had 2 or 3 threads to run, and 4 CPU cores, then, yes, this would be strange. But there are at least a few dozens other things running in the background, that introduce “noise” to the system and make it hard to predict what the best solution is. And you wouldn’t see it just from the global CPU activity graph.
Is it optimal? Probably not. But to answer this you have to define what “optimal” is. First, what do you want to achieve? Lowest possible latency for the user? If so, the mouse movements and all things related to “display” will have to be run first. Or do you want your lame process to run as fast as possible even if the GUI is completely frozen during that time? That’s also possible, you can set your processes with a very high priority. Or maybe, try to keep one CPU core idle as much as possible when it’s not really needed? You can also do that, by switching the scheduler to it’s “power saving” mode (available in ProcessController menu). And, also, the scheduler has to make decisions very fast. If it spent 2 seconds computing the perfect solution everytime it needs to select what thread to run on what CPU, it would not be optimal anymore, even if the solution would be the theoretical perfect one. The scheduler is an O(1) algorithm, meaning it does not scan all available CPU cores and all available threads when it wants to decide what to run next. And so, sometimes it has to take a shortcut and pick the “good enough” solution that can be done very quickly, rather than the perfect solution that would take too long to compute.