Hi everyone,
I am a second year (ending) CS Major student with a lot of interest in algorithms, optimisation, and OS level work.
I’m considering submitting a self-proposed project for GSoC 2026: implementing a custom CPU scheduler for Haiku called DPS (Democratic Process Scheduler).
The core idea is that instead of treating scheduling decisions as purely individual, DPS lets tasks vote for each other based on observed inter-task relationships — waker identity, burst patterns, and reinforcement-learned preferences that persist across process lifetimes. Short-burst latency-sensitive tasks get classified as “institutions” and bypass the election entirely for fast dispatch. The goal is better system responsiveness for structured workloads like desktop pipelines and game loops.
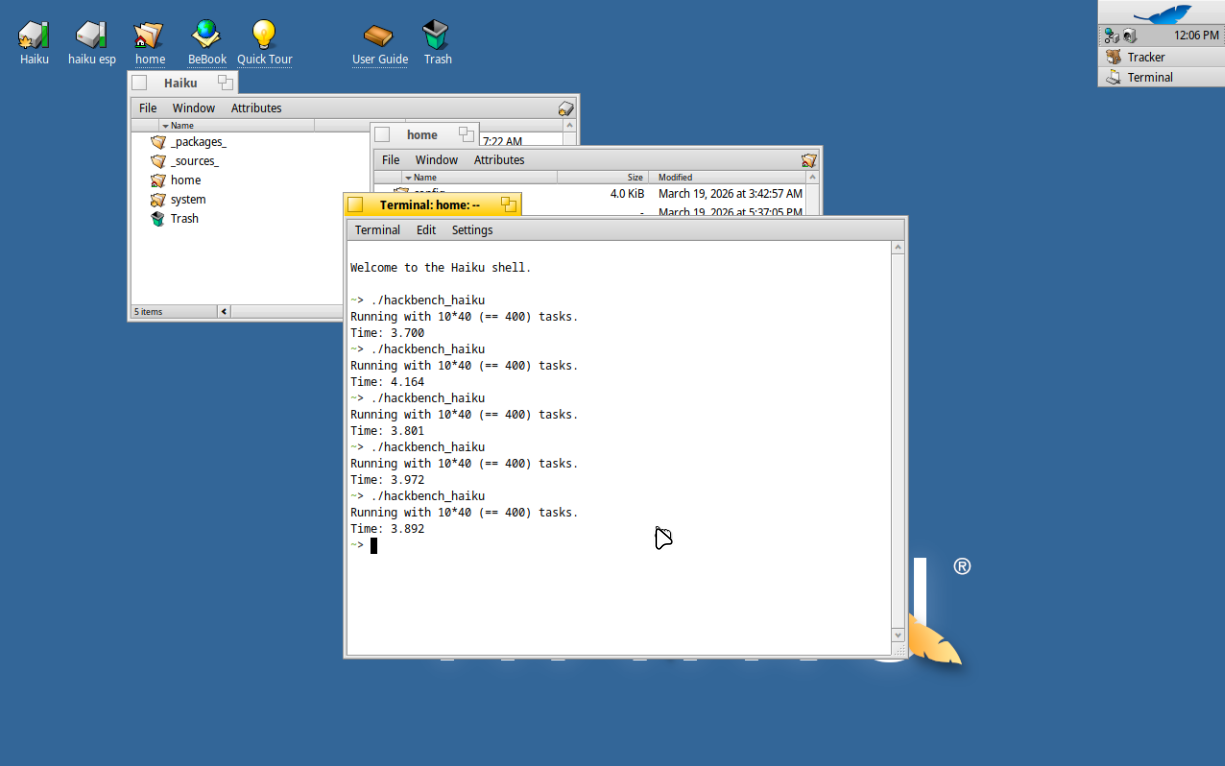
I’ve already implemented this on Linux under the sched_ext framework (merged in 6.12) and benchmarked it against BORE, scx_bore, scx_bpfland, scx_flash, and scx_rusty. The headline results on a 4-core Haswell: schbench p50 wakeup latency of 10 µs vs 152 µs for BORE, p90 of 43 µs vs 1942 µs, and significantly better worst-case RT latency on cyclictest. The tradeoff is ~11% lower throughput on embarrassingly parallel CPU workloads with no inter-task structure, which is expected.
The GSoC project would involve porting this logic from sched_ext to Haiku’s native scheduler framework — adapting the preference learning and dispatch tiers to Haiku’s thread/team model and benchmarking against the current affine scheduler. It’s a substantial scope, but having a working reference implementation should make the design decisions concrete rather than speculative.
A few things I’d genuinely appreciate guidance on:
-
Is the Haiku scheduler architecture documented anywhere beyond the source? I’ve been reading through the kernel source but would love pointers to any design docs.
-
Are there mentors with scheduler/kernel experience who’d be interested in this kind of project?
-
Any known limitations or constraints in Haiku’s current scheduler I should be aware of before writing the full proposal?
Thanks in advance, and please, do tell if this isn’t at the top priority.
It would seem attaching links led to the post being hidden, so I won’t be attaching them.