Well, it won’t really be easy for you to work on scheduler latency without being able to work on bare metal. Does Haiku not run on your hardware?
Haven’t tried it actually, but I do have a spare hard drive I could run it on. I think the main issue would be switching back and forth from my main system to Haiku for testing builds and etc, which is slightly inconvenient but absolutely doable. Should I consider committing this to the main build for GSoC?
What do you mean by “to the main build”? If you mean the main repository, it’s a third-party tool, so it belongs at HaikuPorts.
my apologies, I was assuming I had to make the commit to the main haiku repository on gerrit. So, I make a pull request on github then, and add the file as part of perhaps under a dev folder? the benchmarking suite would live in HaikuPorts as a collection of ported tools, while the DPS scheduler implementation itself would go into the main Haiku repository as a new scheduling mode. Is that the right way to think about the project scope for GSoC?
If Gentoo already has some tool, then it goes wherever Gentoo Portage placed it; HaikuPorts generally follows its categorization scheme.
A new scheduler implementation would go in the Haiku project itself, yes. However I can tell you that you certainly won’t be selected for GSoC without some sort of notable code contribution relevant to your project. For a kernel project, porting a userland tool from Linux doesn’t really qualify.
Could you give me suggestions perhaps on what to contribute then? I assume even touching the kernel level code would be scrutinised heavily, but then I also have to make a proper contribution. Since I am looking to apply for a scheduler implementation, I would have to implement in that area, yes? But then, I am not really sure the reviewers will accept it without a lot of testing themselves. Any suggestions?
That’s true of just about any change, not just kernel ones. If you’ve implemented an entirely new scheduler mode for Linux and are proposing of your own accord to write a new one for Haiku, then I think you should be able to find something in the current scheduler which could be improved, or implement some sort of profiling inside the kernel demonstrating what your proposal would seek to improve, or something like that?
1 Like
The second option sounds more viable, considering if no one has touched the current scheduler code for about a decade (implemented in 2014 from what I can see), it must be good as for now, and actually adding improvements would be tiny increments, if any are to be spotted.
would exposing metrics like wakeup latency and context switch times via a kernel debug interface be the kind of contribution that would be considered?
It’s definitely been touched since then, there have been a variety of minor improvements here and there. You can check the commit log.
We try to add things that make sense. So, do you have a good reason why that (or anything else) makes sense? Then even if we have not thought about it before, we will probably accept it. But if it’s just numbers for the sake of numbers, then we probably will not be inclined to accept it.
The reason is straightforward, without baseline scheduler metrics exposed at the kernel level, there’s no proper way to evaluate whether any scheduler change is an improvement. The GSoC proposal involves implementing a new scheduling mode, but claiming it performs better means nothing without a way to measure the current scheduler’s behavior first. The profiling would serve as the measurement foundation for all scheduler development going forward, not just my project. A baseline benchmarking/profiling tool has to be a must to be able to measure improvements in the code itself.
1 Like
But what are these metrics, and do they need to be exposed at the kernel level?
“Scheduling latency” is measurable from userland (as you ported a tool to do, I think.) “Context switch overhead” is a bit harder, but this would be identical no matter what scheduler mode would be used, and it’s usually most valuable to measure this in userland too because then we get interrupt overhead properly measured also.
So, what “baseline scheduler metrics” do we need that we can’t measure more effectively from userland?
while most can be measured from userspace, run queue wait time for threads is something that is more better measured from the kernel than the userspace, as the latter also includes latency from syscalls overhead. I think that’d be a good enough contribution, mind you, this can still be measured in userspace, but my contribution would remove the noise that comes with it and give pure kernel performance. that said, I’m open to your guidance on whether that distinction justifies a kernel contribution or whether a userland measurement would be good enough for this too.
in fact, i think the current code already exposes all the data required to compute it, but doesn’t seem to have been implemented at all.
There are already a number of scheduler-related KDL commands to dump various pieces of information. Maybe you can see if it’s already in one of those, or if not, where it would likely best fit in?
from what I read in the code, specifically, scheduler_profile.cpp and scheduler_tracing.cpp, the current kdl commands are from what I can see- list all cpu cores, idle cores, run queue, and a scheduler thread analysis tool.
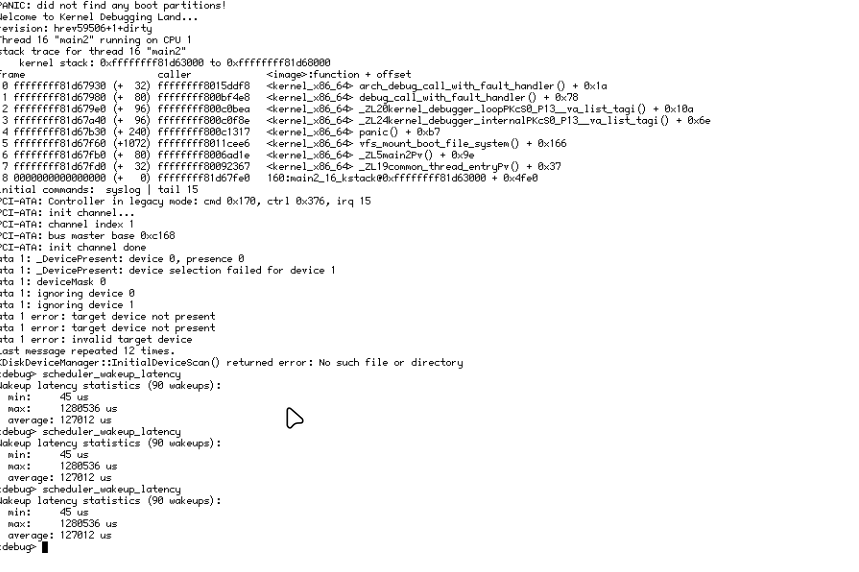
there’s no way to get global wakeup latency statistics without tracing overhead. My contribution would add lightweight always-on global min/max/average wakeup latency counters accumulated in ThreadData using the existing fWentSleep timestamp, exposed via a new KDL command. Same metric as scheduler already computes — just global, always-on, and without tracing dependency.
The current one seems to require scheduler_tracing to be compiled and also requires a thread id to view the results.
Hi shan10u. I bumped your forum trust level to member. The forum software marked posts of yours as potentially spam since you kept linking to the same server, either google docs or github ![]()
1 Like