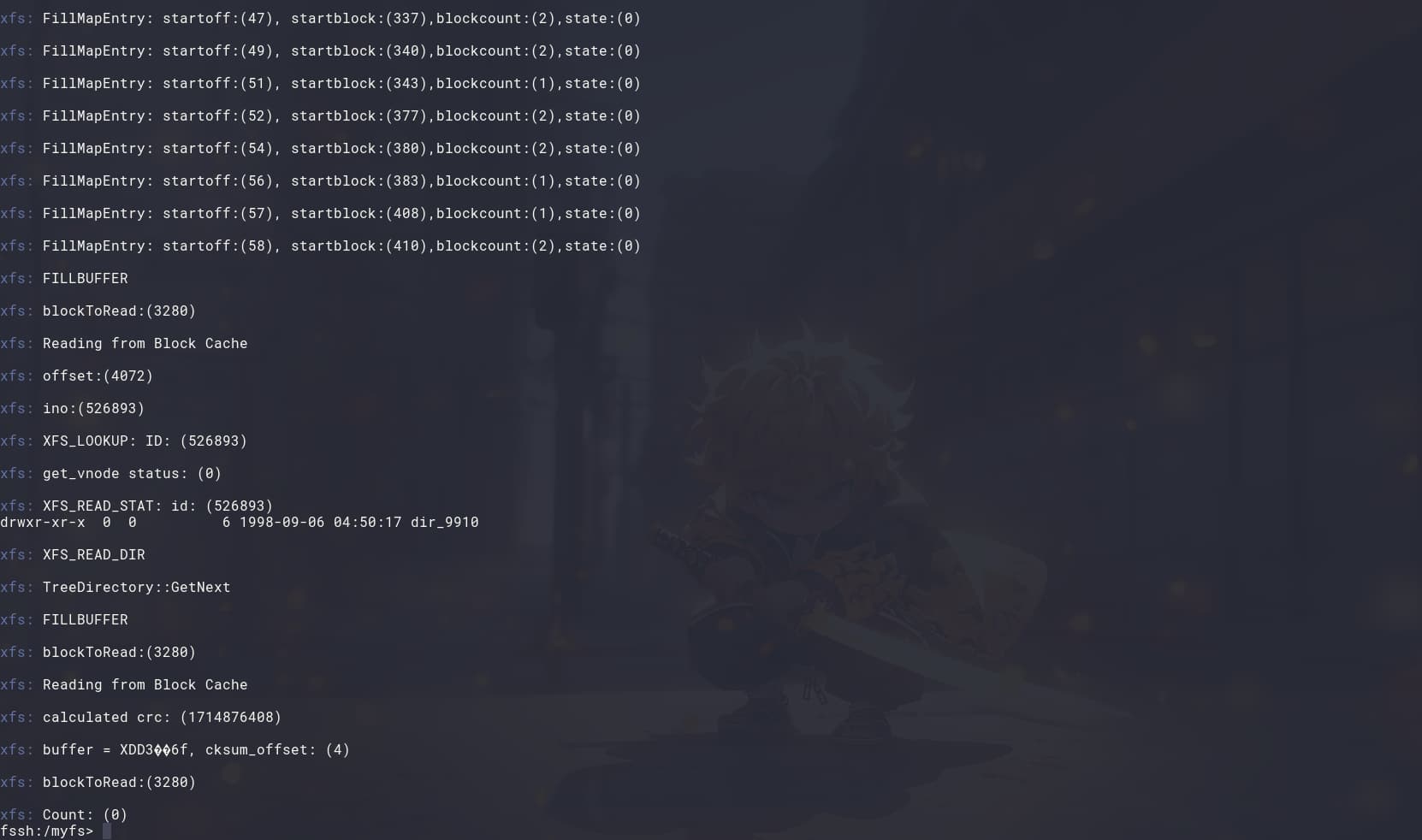
I have successfully implemented Block Cache for directories, ensuring they function correctly within the XFS shell. The buffer allocation has been replaced, allowing direct access to the Block Cache. The next step is to test this implementation within Haiku.
Currently, I am addressing multiple memory leaks in the B+ tree implementation. One issue I encountered was that B+ tree directories could not be read through the XFS shell. While working on this bug fix, I identified and resolved the root cause.
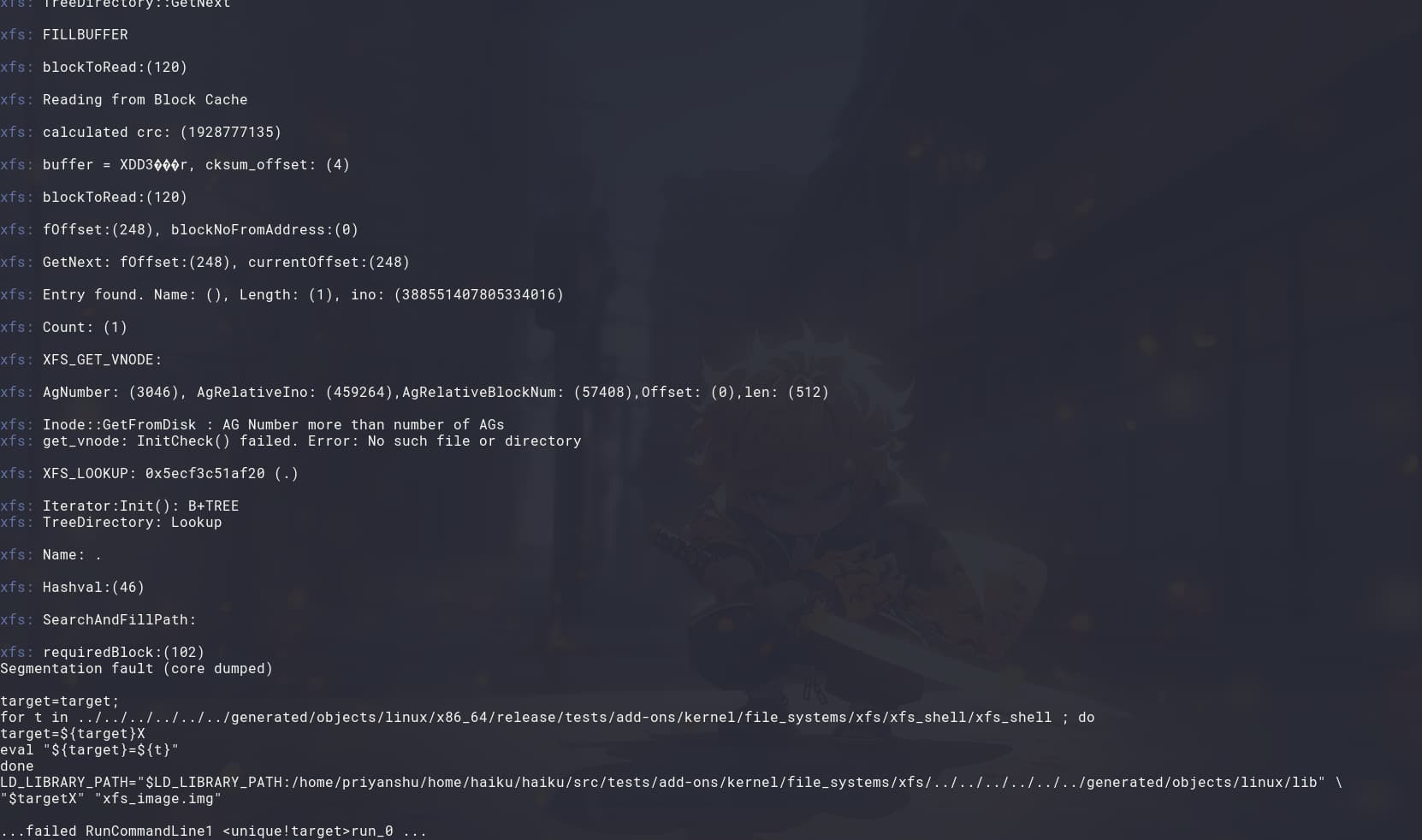
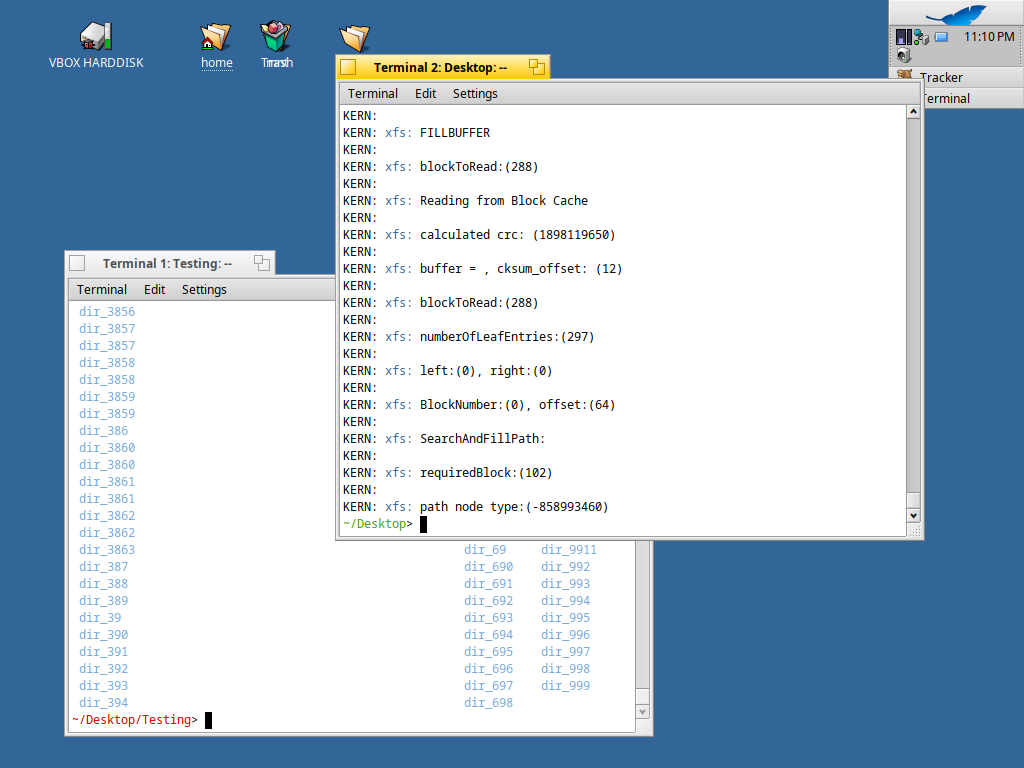
To detect potential memory leaks, I have been using Valgrind. Interestingly, while the code is still not functioning correctly under normal execution, running it through Valgrind allows me to successfully read the entire set of B+ tree directories (~9910) without any issues. Does someone have any suggestions regarding this unexpected behavior? Attached are images demonstrating the B+ tree directory reading operation within the XFS shell.
I am still in the process of refactoring a significant portion of the code to eliminate potential memory leaks. I will definitely look into this suggestion. Thank you for your input!
I have successfully compiled the XFS driver with the Block Cache and tested it out inside the Haiku; however, the same issue persists when reading from the Node directories. The kernel enters panic mode due to an incorrect block number in the block_cache_get() function. Interestingly, this issue does not occur when using the XFS shell, and the system behaves as expected when using the syslog command. After the panic event, the block cache appears to function correctly with the node directories, and the tree directories are accessible without issues but the delay is there and they are displayed once all the reading is finished.
I am interested in understanding the implementation of the Block Cache as described in this file. Specifically, I would like to gain insights into the actual code implementation, including:
How blocks are cached
The size of each cached block
Whether multiple blocks are cached simultaneously
If multiple blocks are not cached by default, I would also like to know how multi-block caching can be enabled. Any detailed explanations or references to relevant parts of the implementation would be greatly appreciated.
I assume you are running the xfs_shell on Linux. In that case, it may be possible to build it to use gcc or clang sanitizers (libubsan and libasan). This would provide more extensive checks than even Valgrind can do. Maybe it will help find more memory misuses.
Fixing any warnings detected by Valgrind is also a good idea before going further.
the API seems quite simple to me from that file.
First, you create a cache using block_cache_create. You have to give it:
A file descriptor: pointing to the partition where your filesystem is stored. The block cache will take care of reading and writing to disk for you
The block size of your filesystem (this is the size unit that the cache will work with. You cannot request smaller or larger blocks from the cache, everything is exactly this size).
The number of blocks in your filesystem
Number of blocks multiplied by block size should match the total size of the filesystem in bytes.
Then, you access the filesystem using the block_cache_get* functions. These function either directly return a pointer to the cached data, or return it through a modifiable function parameter.
If your filesystem is read-only, you only need the basic block_cache_get function, that will get a block from disk (or from the cache, if it’s already there). When working on write support, you will need to request “writable” blocks when you want to make changes, and you can also request “empty” blocks when you are going to completely rewrite a block, and you don’t need the block cache to first read the previous content. You can also discard a block to inform the block cache that its content is no longer relevant, and does not need to be written to disk.
There are also functions to turn a read-only cache block into a writable one, as well as attaching a write operation to a cache transaction.
When unmounting the disk or when the sync command is run, you should use block_cache_sync to make sure all data is written to disk.
All these APIs operate on a single cache block at a time. If you know that you are going to read several consecutive blocks in one go, you can tell the block cache about it using block_cache_prefetch (giving the first block, and the number of blocks). The block cache will then start caching those in the background, which means later, when you actually access them using block_cache_get, the blocks will already be in memory and the access will be very fast.
Whenever you use one of the block_cache_get* functions, you must free the block using block_cache_put. If you don’t do this correctly, you will have memory leaks.
If you are curious about the implementation of the block cache, you can read its sourcecode (src/system/kernel/cache/block_cache.cpp). It mainly consists of:
A hash map to keep track of the blocks currently cached
A thread to perform the reading and writing
Synchronization primitives so that the code calling the block cache API can safely cooperate with that thread
A registration with the low resource manager, that allows the kernel to tell the block cache when memory is running low. Until this happens, the block cache will just try to keep all the blocks in memory.
When you are running your filesystem as a Haiku kernel driver, the block cache also offers some debug commands in the kernel debugger: block_cache, block_caches, cached_block, transaction and block_cache_data. These can be useful to check how your block cache is behaving, which blocks it stored and what’s in these blocks.
I have pushed my work related to the Block Cache implementation, and it is working fine on my end. The patch can be found here: patch. Could you please review it when you have some time?
Currently, I am working on code refactoring to address memory leaks. The progress is going well, but I am encountering some unexpected behavior. I will investigate these issues further and keep you updated if I have any questions.
Recently I’ve been busy on other projects and did not have much time to do code reviews for Haiku. I hoped that someone else could take a look. I’ll see if I can find some time this week where I’m not too tired and I can do a useful code review