I’m going through the Read support of the Xfs system and I talked to a (Gsoc 2022) contributo and referred the resources he suggested. the first course of my target is to visualize the data layout in the disk which is going well. I’m currently looking at the functionality of the directories, and then I will come to Symlink. During my digging, I came to a confusing error. there is a structure in https://github.com/haiku/haiku/blob/master/src/add-ons/kernel/file_systems/xfs/Extent.h
ExtentData entry it seems that the ftye and ftag field is missing which is further used here in
https://github.com/haiku/haiku/blob/master/src/add-ons/kernel/file_systems/xfs/Extent.cpp
In this there is a function named EntrySize in which the entrySize has addition of 16bits(for tag) and if it is ftype inode then add (8bits) for ftype so my question is does the original structure should include ftype and tag field. the doocs are suggesting the same.
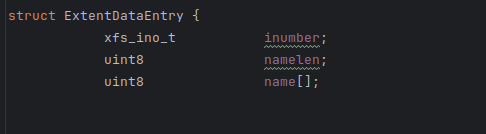
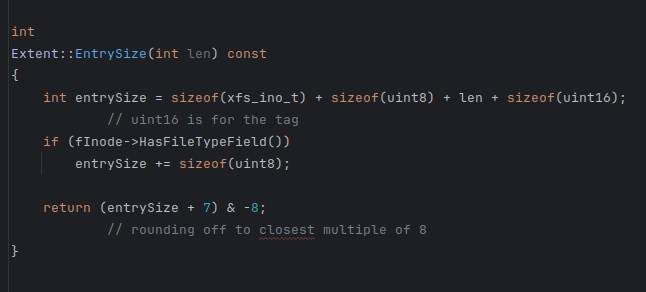
No.
Please note that the structure you are reading has variable size due to name[ ] field at last.
The comment there says after name field we will have two data fields in structure whose on-disk offset will be found at runtime.
Firstly to create a file,there should be a way to manage free space and a way to map free entries.Should i start with implementing these functionalities for adding the write support to xfs?
If you look at the inode class, for example here:
You will see that it is trying to handle multiple versions of XFS. In later versions, more fields were added. But it is not possible to represent these in C++ structures directly, because they are not always available. So, the data is extracted manually by computing the appropriate offsets in this case.
Regarding the free space, I think you have to find the information in design - xfs/xfs-documentation.git - XFS AsciiDoc Documentation tree (there used to be a browsable version online at xfs.org but it seems to not exist anymore ![]() ). In particular, for writing, you have to read about “allocation groups”, and probably as well about journaling (the way the write operations are done so that nothing is corrupt if there is for example a power cut during a write).
). In particular, for writing, you have to read about “allocation groups”, and probably as well about journaling (the way the write operations are done so that nothing is corrupt if there is for example a power cut during a write).
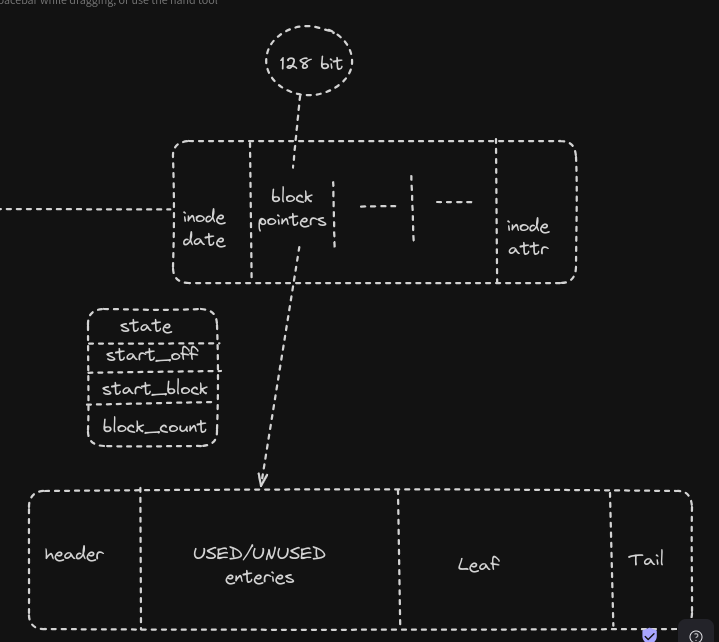
This is the diagrammatic representation of what I have understood about the block directories from the Read Support From Extent Section in XFS. Can anyone verify whether this is the Correct Implementation of the Block Directories If yes, can Anyone answer these-
- if only 128 bits are required to locate the extent in Block Directories then what about the remaining Area of the INODE?
- What if we can find any Extent that has a size Equal to the Directory Block size?’
- Are we filling the leaf Entries from the tail backward or for every new entry we have to move previous leaf entries to the left and then insert the new entry to the tail of the Extent?
Testing using Xfs Shell return in Build Failure. I tried to trace the path of the Error It seems to be related to DeviceOpener.h File But Don’t Know how to Fix it can someone help me.
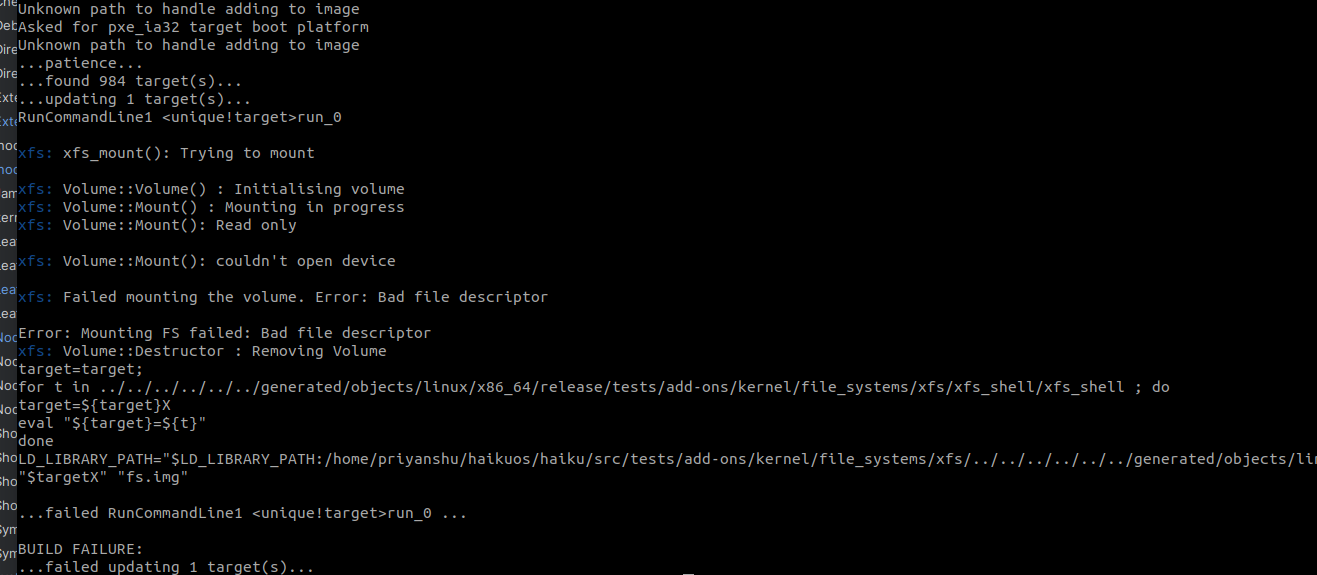
In this screenshot there is no build failure. The XFS shell is built and run. But it is unable to mount the XFS filesystem that you gave it. Are you sure you are giving it a valid XFS filesystem image to test with? It is hard to say, since in that screenshot we don’t see what command line you used. In general, it’s better to provide a text copy of the complete build log, rather than a screenshot of part of it.
Regarding directories.
I found a PDF copy of the XFS documentation that is easier to browse and reference. https://mirrors.edge.kernel.org/pub/linux/utils/fs/xfs/docs/xfs_filesystem_structure.pdf
Looking at section 17 in this document.
The most common case (when there are few entries in a directory) is a “short” directory. This case is quite simple. We start from the main inode of the directory. This has a header with the number of directory entries, a pointer to the parent, and a counter of 64bit entries. Then there is the list of entries directly after that. Each entry has a name, a type (directory, file, …), and an inode number (where we can find the data for that entry) as well as a few helper fields for finding the next entry in the directory.
Now, the entries will at some point fill the inode entirely. At that point, we switch to “block” directories. These store the directory entries outside of the inode.
In this case, the inode does not directly contain directory entries, instead it contains an extent list as specified in section 16.1. This is a list of places on disk where directory blocks are found. The list will be more or less full depending on how many blocks are used to represent the directory. In the case of files, this works as you expect, using more and more entries in the extent list as the file becomes larger and more fragmented. But for directories, there is special handling for a case where the entries and “leaf” data can both fit into a single block. This is what “block directories” are: too large to fit entirely directly in the inode, but too small to deserve use of the complete “leaf directory” format. In this case, there is always only one extent used, and the remaining part of the inode space is not used at all.
An extent is just a [start, end]interval on disk. If you have an extent of just the size you need, you can use that. If you have a larger one, you can split it into two smaller extents. If you only have small extents left, because the disk is almost full and fragmented, you have to use the “leaf directory” format and use multiple extents.
From the book:
“The tail structure specifies the number of elements in the leaf array and the number of stale entries in
the array. The tail is always located at the end of the block. The leaf data immediately precedes the tail
structure.”
I think it is not really “fill from the back”. What happens is, the leaf structure is first built in RAM until it is time to write it back to the directory. At that point, you have to check if the leaf structure still fits in the remaining space (if not, the block directory will have to be converted into a leaf directory). Then, you write it, “right aligned”, that is, so it ends just before the tail.
There doesn’t need to be an exact match between the in-memory representation that the code works on, and what ends up written on disk. The “conversion” can be done when reading and writing data. So, by having the in-memory data managed as two independant memory allocations (the leaf and the entries, which can grow independently), you can delay the computation of the exact on-disk layout (where to start the leaf in the block) at the last moment, when the size of the leaf structure is known.
I hope that answers your questions clearly enough.