The way you created the image seems correct. Probably something is wrong or missing in our xfs code.
The error and debug messages are not very clear, so a good first step to investigating this would be adding more debug messages to the xfs code, or see if it can have extra tracing enabled at compile time (usually by defining a TRACE_xxx macro in the sourcefiles where you need tracing). Then it will be easier to see why our xfs code is nottable to understand your test file.
I was able to read the files in that image using xfs_shell, to do some more testing I added my own directories in that image and successfully tested 10k directories.
To look why my image was giving error I checked the version of XFS in both the images.
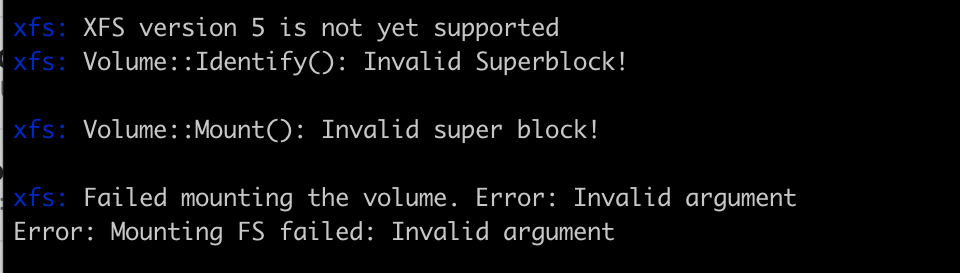
My XFS image has XFS version 5 while the image I successfully tested has XFS version 4.
This gives us an idea that in our current state we are not able to read XFS version 5 images.
I think the idea was to implement the older versions first and then gradually add the new features. However, this should fail with a better message like “xfs version 5 is not yee supported”, for now
Can we make the changes in source file to give better error message?
For eg : when I tried to run command mkdir it has given “Command not supported yet” we could make same for XFS version 5 as well I guess, though right now I don’t know how to do that though
Anyways I will continue my testing on xfs version 4 image.
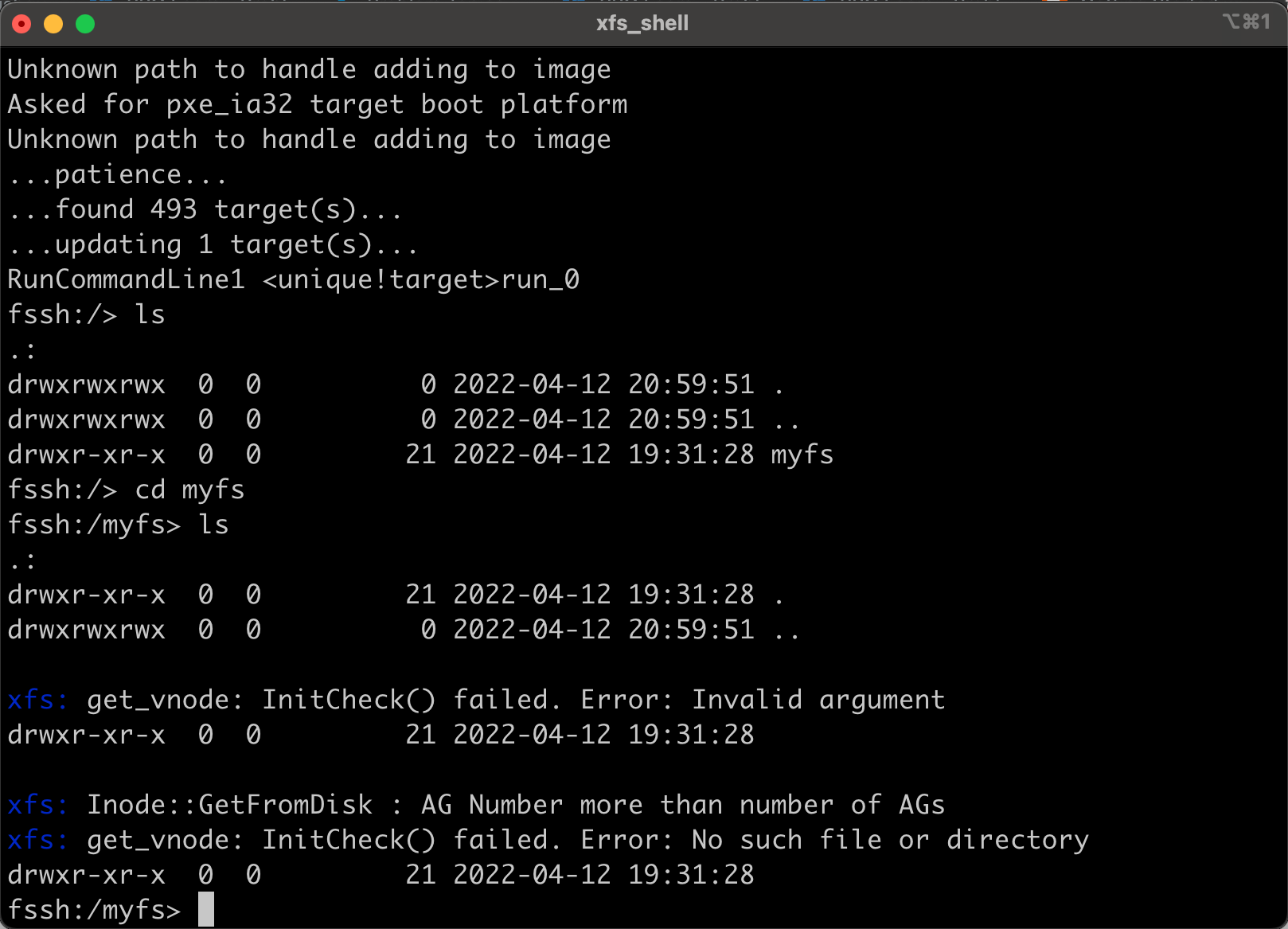
I encountered some segmentation fault on running ls on directory with 20k directories.
Its very strange though, at first I was able to read completely upto 20k but when I ran ls command again it has shown segmentation fault after reading 6k directories.
Some large directories are showing same segmentation fault : 11 error.
Looks like this error wasn’t resolve last year.
Any guide on how to fix this?
For segmentation faults, maybe you can use a debugger to investigate them, get a stack trace, and see where is the code it’s crashing.
Or just add a lot of TRACE() call everywhere in the code to see which parts of the code are run, and where it’s failing.
You can look in more details at the build logs. Probably some of the TRACE calls are incorrect and need to be fixed: wrong format strings for example (the format strings work like the ones used for the standard C printf function)
I thought so…
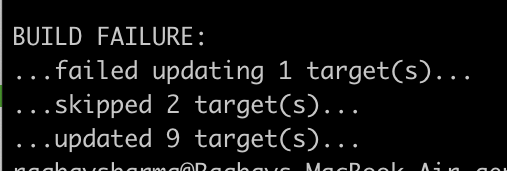
Good thing is only one file failed to build, so its going to be easy to debug it.
I will look at build logs to find that file and incorrect trace call.
whenever we try to run xfs image version other than 4 its going to show us error due to ASSERT function.
Considering now linux builds xfs images in version 5 I tried to create a new block here specially handling version 5 case and got satisfactory error message.
I think for now I will try to debug that segmentation fault we encountered while testing and see if I make some progress there.
If not then I will look for v5 support or maybe extended attributes feature.
I need help in attaching debugger to xfs_shell.
I am using lldb debugger.
Steps I am following are :
jam run xfs_shell as usual.
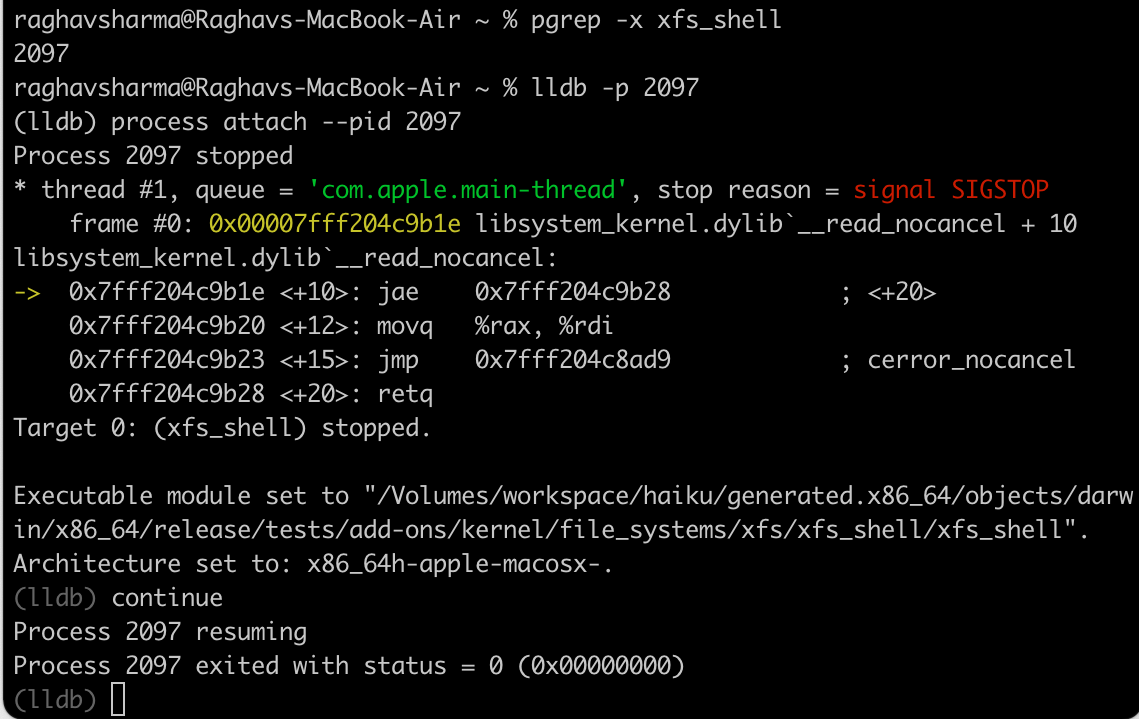
Get pid of xfs_shell using pgrep -x xfs_shell command.
open new terminal window and run lldb -p pid_of_xfs_shell .
Now lldb attaches itself to xfs_shell but there is initial SIGSTOP I guess due to my local machine.
Anyways when I command continue process simply exit with status 0.
I tried to look for some solution to this situation but didn’t find any
The Ideal situation should have been process getting continued and then I would have been able to generate segmentation fault as usual in xfs_shell and get backtrace in lldb.
Actually This is almost same as the process I applied and unfortunately gave me same results.
Anyways I tried to get GDB on my local machine and I am able to actually continue process using GDB debugger, but the problem now is whenever a segmentation fault occurs xfs_shell terminates entire process.
So when I try to reproduce segmentation fault for GDB to catch it, we can’t get any trace as xfs_shell terminates and GDB gives result as
Inferior 1 (process ___) exited normally.
If we could get xfs_shell to not terminate we can then get a backtrace.
I think I should ask this on mailing list to get other developers help as well.
I’m not familiar with how lldb works. It’s strange that gdb would not see the segmentation fault.
An option is adding code in xfs_shell to “ignore” the SIGSTOP signal and not exit when receiving it.
Another option is to start the process from inside lldb (using it’s run command) but I am not sure how easy it is to do this (since you need to replicate what “jam run” does). Maybe other developers can share their tips indeed.
In my case I run these things inside Haiku, and in that case, I can attach Haiku Debugger after the crash occurs, which is very convenient. I don’t know why this isn’t the default behavior in other systems.