I’ll weigh in my 2 cents as somebody who studied Japanese in college for years, while I’m not that good with it I might help you clarify what you may perceive as confusing statements, because frankly they probably are if you are not familiar with how “sinograms” (Chinese characters) work.
I’ll make it short or else I might go on a tangent, each country that adopted the original Chinese characters in some form throughout history has molded them with use.
In this scenario we’re talking about the 2 modern Chinese variants, simplified (with generally less complex characters) and traditional (which generally stuck closer to the classical Han-era characters), each of them has been adopted by their respective government in an attempt to standardize writing, simple as.
('cause if you don’t do that the writing situation can become extremely chaotic very fast, as people would be able to add their own flourishes in the characters etc.)
While I cannot claim to know Chinese so take my opinion with a good amount of salt, I am not aware of any variant of sinograms for Chinese that is as widespread and used as either traditional or simplified, every Chinese speaker in theory should be able to read one or the other, any other possible set (for Chinese) should be some slight variation on those two at most, but probably it’s like different names for the same thing(s).
Personally if I know the Kanji equivalent I can read (as in more or less understand the meaning) and recognize its Chinese variant most of the time, be it traditional or simplified, so imo even in the hypothetical edge case a Chinese speaker is familiar only with some obscure variant of those they should be able to navigate the interface well enough using one of the two standards, because they can all be traced back to the same root character system.
Or as yjwork put it:
These two alone should be enough to cover 99% of Chinese users’ expectations.
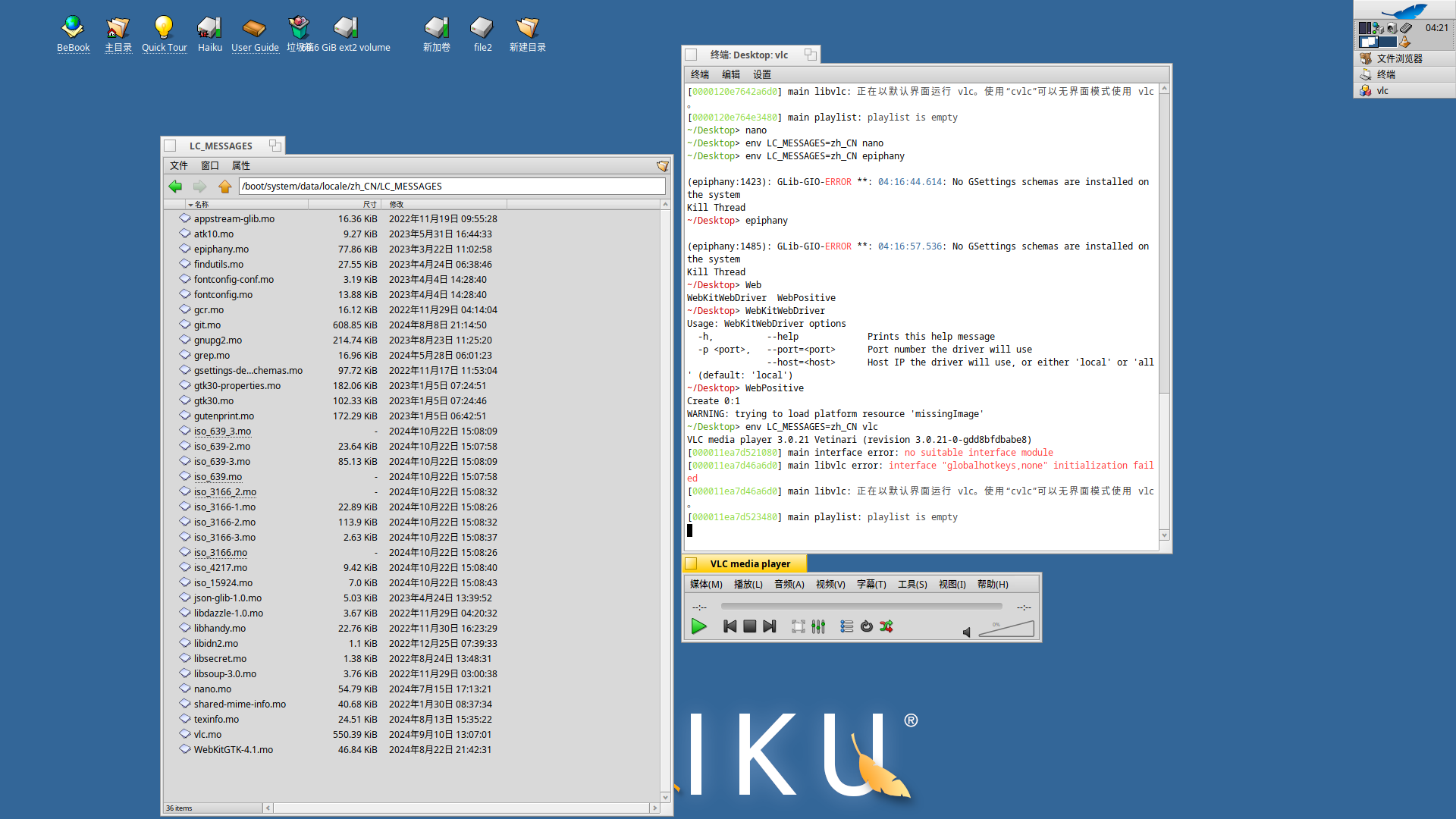
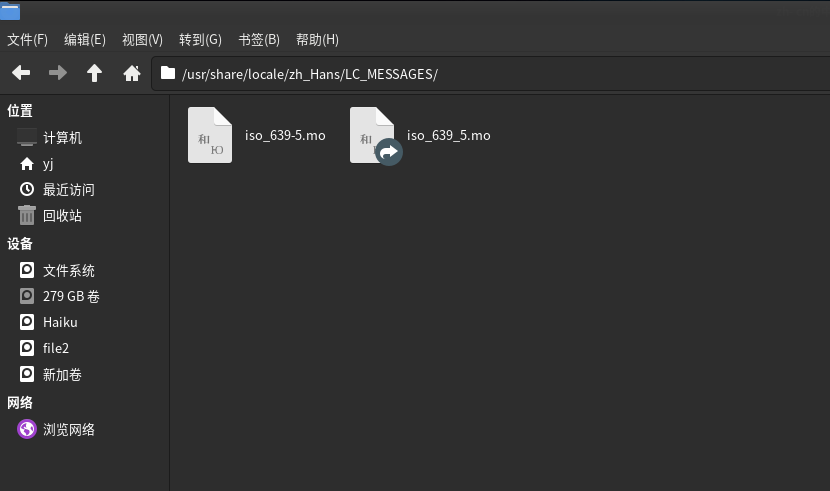
As for the confusing part, I’ll blame that subroutine example, as the characters used there are actually not the same, both in writing and meaning afaik.
Probably worth keeping in mind that, as KENZ noted, Chinese users should generally be more accustomed to zh_CN and zh_TW, though I get that zh_HANS and zh_HANT don’t refer to actual countries.