Hey, thanks for the reply! I partially agree with the Siri sentiment. Other than certain times when I’ll use Siri on my phone or tablet, I don’t care for her that much either (i.e. on my modern MacBook Pro, it’s disabled.) Too much data going to someone else’s server for no good reason (“processing” works just fine on an old G4!)
What I was actually referring to were the pre-“Cloud” days (still working for me) on my classic Macs where MacInTalk voices and localized recognition were used… and as far as recognition went, speech was just the person and the computer with no “modern” corporate spying nonsense in between.
That said… here’s screenshots for the Haiku community and team to see how text to speech prefs on Mac OS X (10.1) and 9.2 looked like, so maybe TTS can be implemented on Haiku in the future. 
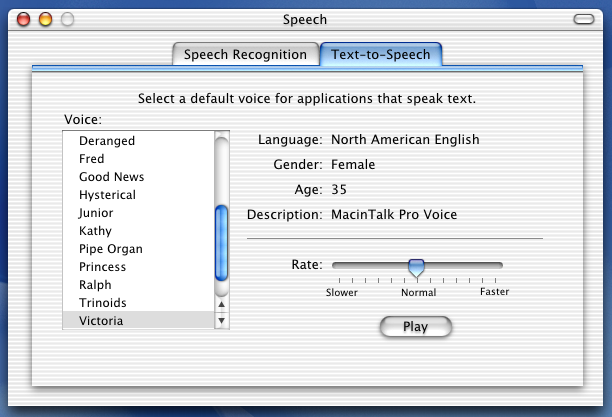
Mac OS X not only read alerts and the time (by hour or up to quarter hour; not shown here), but also had full text-to-speech services for all Carbon and Cocoa applications. I chose to show 10.1 here, as it was still very simple. If you haven’t used a Mac from 10.6 or earlier, several voices are meant to be silly, like Bells or Deranged. The ones with names are serious characters – the best ones, imho, are Bruce, Fred, Victoria.
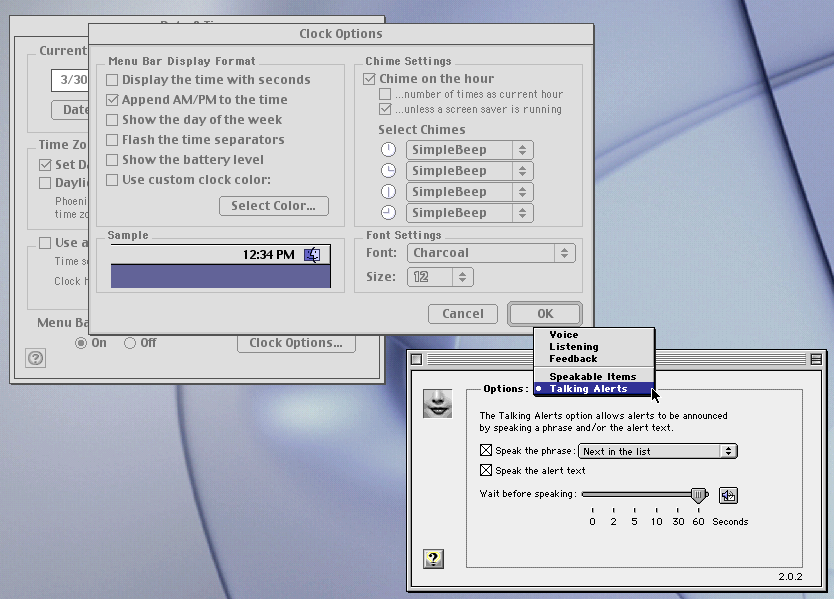
Here’s MacInTalk speech (English) on Mac OS 9.2 on my Power Macintosh G4. I opened Date & Time and expanded out the list of five areas in Speech so everyone can get a visual example of what’s available in it for those that no longer have Mac OS 9. Only “Voice” and “Talking Alerts” controlled speech synthesis. The “Speakable Items”, “Feedback”, and “Listening” options were all part of speech recognition – (while off-topic, a box would appear that looked like this):
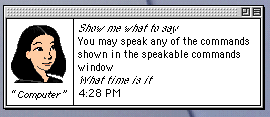
So, the prefs shown above is more or less what I was referring to (minus the above box). The idea is just to have a friendly speech synthesis service and control panel, and maybe have a localized AI on the system (no cloud) in the future. I wouldn’t wish for Haiku to ever have cloud assistants (i.e. Siri or the like). I was comparing voice quality to modern-day cloud assistants (Alexa, Cortana, Now, Hound, Siri), as they are the most well-known. But even the MacInTalk voices like Victoria didn’t sound all that bad, I think. Maybe that’s just me.
My point is we could add speech in with free/open voices. And we really could beat Fedora, etc. here as I don’t believe they’ve reached this point yet! I don’t know… maybe I’m just optimistic about the future and want to see Haiku grow. But it’d sure be fun to have… and I don’t know… I just might be willing to work on this when I’ve got extra time, rather than just talking about it. 
It’d still be fun to read what people think of speech though. But anyway, thanks all.
 which I haven’t found built-in anywhere else. I find espeak and similar sound sadly robotic compared to every non-free voice from Alexa to Siri… and I think Haiku would have to use voice clips generated from another system temporarily… so I’m not suggesting Haiku reading anything dynamically, etc. as I mentioned in another speech-related thread before.
which I haven’t found built-in anywhere else. I find espeak and similar sound sadly robotic compared to every non-free voice from Alexa to Siri… and I think Haiku would have to use voice clips generated from another system temporarily… so I’m not suggesting Haiku reading anything dynamically, etc. as I mentioned in another speech-related thread before.