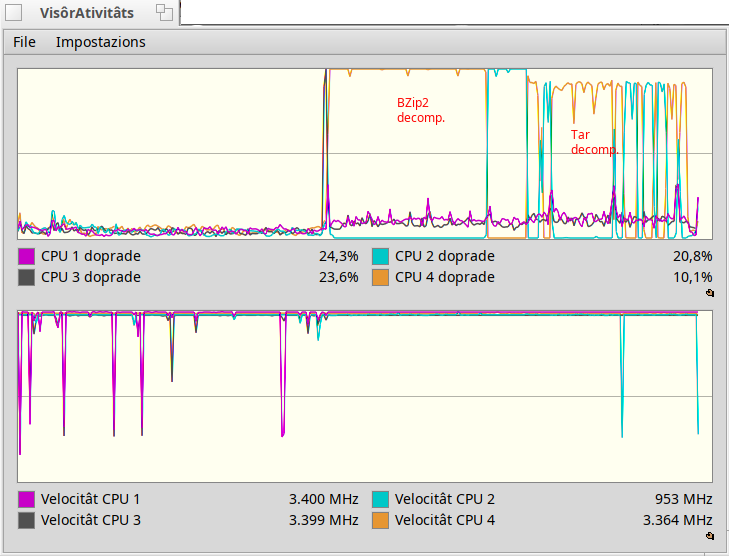
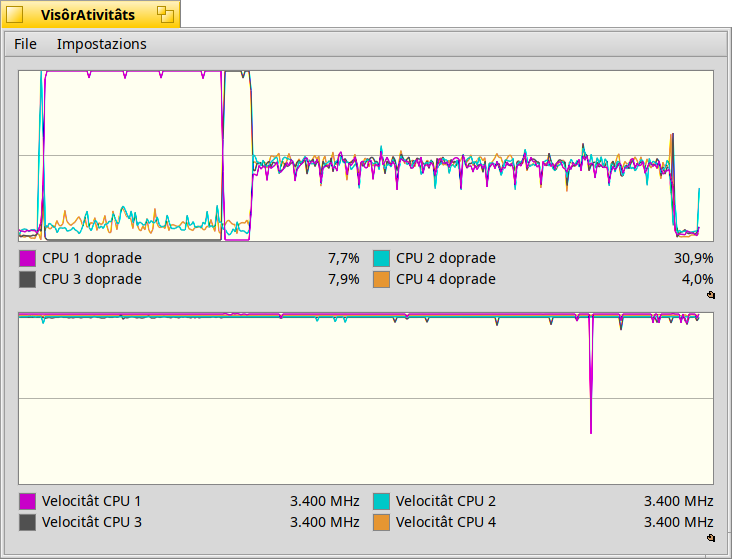
Hi people,
I’ve managed to produce a simple app in python, using Haiku-PyAPI, that inflates and deflates tar.bzip2 archives. The special effects here are two:
-
The bzip2 part is parallelized, thus taking advantage of multi-core/processor systems
-
The app archives the specific attributes stored in BFS filesystem and restores them at decompression-time.
To all intents and purposes it creates tar.bzip2 archives, so in fact you can extract them with the relative tools. But if you do this way, you’ll get along with your original compressed files, files containing the attribute data.
This made me think about whether to use a different file type or continue using the tar.bz2 extension. It would be nice to open a vote to let you choose what to do.
In the meantime, I’m posting some compression size/time benchmarks that everyone loves.
Here’s a single big file compression using:
- original tar command with bzip2 compression (that doesn’t store the BFS attributes)
- my app
- zip command
The test file used is a randomly chosen file from the net, a soundfont2 (.sf2)
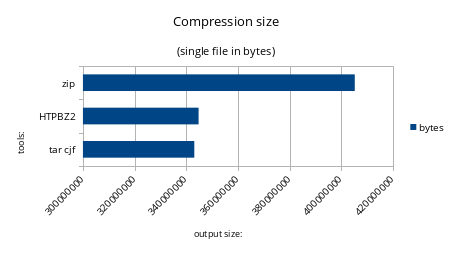
As you can see the output size is slightly greater than original tar/bzip2 compression, this is due in part by the little overhead introduced by bzip2 parallelization and in part by the attribute data stored.
To be precise, the data are these:
- tar-bzi2 = 343106781 bytes
- HTPBZ2 = 344757164 bytes
- zip = 405221672 bytes
Zip format compression is weaker as it was expected in this benchmark.
But on the contrary, it excels in processing speed as you can see in this graph:
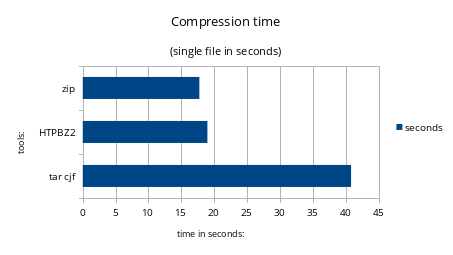
here you can see that while zip is extremely fast comparing to original tar/bzip2
my app is slightly slower, a difference not very relevant, but huge if compared to original tar/bzip2 compression tools.
the raw data is here:
- tar cjf → 40.82s
- HTPBZ2 → 18.97s
- zip → 17,74s
Now it’s time to compare a multiple files and dirs archive. I used the haiku source folder for this test (not so many attributes to store though)
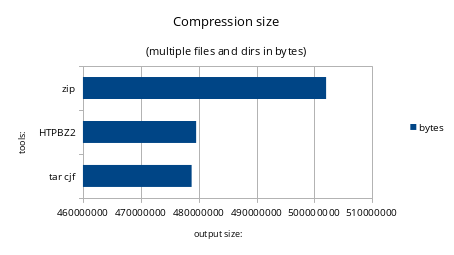
Not so many differences from the previous chart
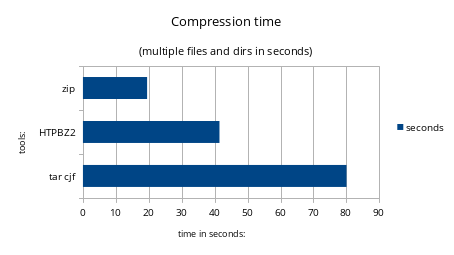
here we can see a slow down, in my app, placing its position between the original compression tools and the fastest zip tool. The possible reason may be that while bzip2 compression is easily parallelizable, tar storege is not. The attributes are added to the archive as files during the tar archive creation time. (but maybe in a future version I can think of a possible solution)
For now, HTPBZ2 is not optimized for decompression, so no need to produce charts comparing timings against tar/bzip2 tool. But it could happen if I manage to improve the code.
If interested the code is on GitHub
The application is still in alpha state for testing reasons and maybe because I’m missing some code here and there ![]()
Enjoy!
Edit: Requirements: Latest Haiku-PyAPI from git repo