@waddlesplash Didn’t Linux specifically swtich to polling or a hybrid handler for NVMe since using interrupts actually causes extra overhead… since an NVMe drive can often reply quicker than the interrupt logic can execute.
Maybe it depends on the drive also, so a cheapo one still can use polling efficiently but a high end flash SSD or Optane SSD almost certainly doesn’t?
Anyway not that it matters much too much since it’s very fast, vs extremely fast we are talking about here.
I have no idea what Linux does since I didn’t look.
I find it seriously difficult to believe that a NVMe driver can reply to a request faster than interrupt logic than execute. Given a drive with 1.4GB/s read capacity and a block size of 2048, the theoretical minimum time (assuming no “burst” capacity faster than 1.4GB/s), to read a block is (1.4GB/2048b = 734,003 blocks/second -> 734 blocks per millisecond -> 0.7 blocks per microsecond) 1.4 microseconds per block. If you are reading just one block, you probably have to double that (or triple that) for all the various overheads there are here and there.
But the number of times that one will transfer “only” 1 block are not very large. Transferring hundreds of KB or even a few MB at once is more likely, and that will take time in the hundreds of uS, which is a large enough unit that the thread scheduler can re-schedule some other thread and do useful work, which we should do rather than polling.
For real world data: kallisti5 tested both before and after my interrupts patch on bare metal, and found that the read performance was still 1.4GB/s in both cases, but CPU usage decreased by about 10 percentage points.
1.4GB/s is hardly the trasfer speed of a “fast” ssd thrse days you either have an older SSD or a slow one, or perhaps a bottleneck somewere?? Or maybe you mean with QD=1
I’m only regurgitation the logic from why they do it that way on Linux… I think it has to do with kernel thread scheduling also… basically if you are using interrupts you are at the mercy of when the thread can get scheduled to come back and look at the data.
For things that take longer that 1ms… interrupts are the obvious choice.
For things that take less than 1ms you perhaps should consider polling… because you have a hot thread waiting on the data…
Also I think the benchmarks they used to determine what was the best course of action took latency of when you could get the data back to the application into account… and using interrupts was hurting that case, as far as I’m aware Haiku’s scheduler doesn’t work any differently in those respects.
IIRC, kallisti5’s SSD actually has a speed of 1.4GB/s, or at least it also gets that on Linux.
Yes, you are at the mercy of the scheduler, and that’s good. If the waiting thread has a real-time priority, it’ll get rescheduled immediately; if not, then it can wait, assuming there are actually other threads that have useful work to do.
Otherwise, if the system is not at 100% load, then you are only waiting for the interrupt latency and the scheduler block to end and you’ll get control back. In either case, switching to polling is a negligible performance impact overall: it may decrease immediate latency, but it’ll burn more CPU cycles that something else could have been using in the meantime, without getting any actual work done.
Also, keep in mind that since NVMe has multiple queues, you have no idea when the driver is actually going to get to your block vs. anyone else’s. It’s highly likely that under heavy I/O load, there are more than 1,000 blocks worth of I/O queued at once (and if some of that are writes, less, in order to hit the “>1ms” threshold in this example.)
And also, keep in mind there is nothing stopping the scheduler from de-scheduling your thread while it is polling. In that case, polling may actually make I/O take longer, because you used up your timeslice and the scheduler won’t re-schedule you until an indeterminate point in the future; whereas with interrupts, you will end your timeslice before it’s actually up and get control back fairly frequently after the interrupt comes.
In that presentation, on page 11, there is a graph of latency and CPU usage for polling vs. IRQs. Polling has an average latency of 4.5us, IRQs have 6.0us. However, CPU usage for IRQs is only 32%, while for polling it’s 100%. So you are shaving about 25% of latency, while also tripling CPU usage!
The “Hybrid Polling” model that they evaluate on the next pages has similar latency, but it still doubles CPU usage. Plus that only appears to be overall latency; “Hybrid Polling” is in later graphs much more comparable to IRQ-based I/O than “Classic Polling.”
So, I think that trading 20% more latency (dubious how observable that is at larger transfer sizes and heavy load), for literally slicing CPU usage by 1/3 or more is completely reasonable, to say the least!
Yes the more I read about it… the more it makes sense why upcoming consoles have dedicated hardware for moving data around from the SSD…
Also in those slides I linked… they were using a dram based SSD device so yeah ideal conditions is an understatement.
Check again that was naive polling, the Linux implementation does a hybrid timeout based polling that ends up basically doubling CPU usage but also decreasing latency… by about 20% in this idealized case 1us-ish.
I literally mentioned “Hybrid Polling” and noticed the CPU usage in my reply…
Also, on page 17, there is exactly the effect I described as being possible above: if you poll too much, the scheduler de-schedules you, and the IRQs then win for latency.
I also don’t know what you mean by “dedicated hardware for moving data around from the SSD”. One way or another, the kernel still has to allocate or copy a DMA buffer somewhere, you can make the fanciest hardware interface you like, but no amount of chips will take the fundamental work of managing who wants I/O and when off the driver. It has to get notified sometime.
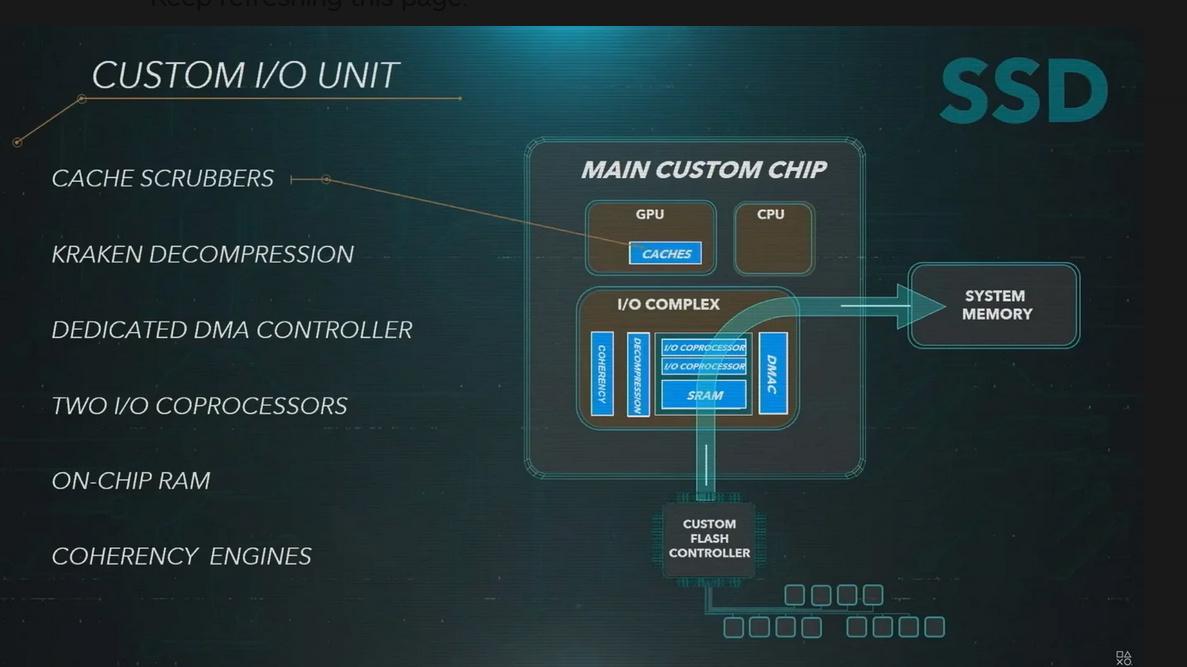
Both APUs AMD is building for MS and Sony have varying degrees of DMA hardware so things can get quickly from the SSD into memory, Sony’s has I think 2 dedicated IO processors etc… which they claimed in the tech presentation that it effectively freed up an entire core of the CPU. I think it ammounts to a virtual memory and caching system… and I suspect AMD’s next gen GPUs will have something like that, basically the next iteration of HBCC.
Sony’s IO processors are hardware decompression engines, not DMA. That’s a completely different thing.
I mean, just from a theoretical standpoint, there’s no way to “free up” CPU cores here. The only thing you can do is decrease interrupt latency or something like that. If a thread’s waiting on I/O, it’s waiting on I/O, and no specialized hardware will help the kernel when the interrupt occurs.
Well I think what they did here was move that function of the kernel into the hardware… so it’s more like the kernel says hey move this there, and then here is now a dedicated processor for that that does nothing but poll and move data around and maybe wrangle the other features of the IO hub. and since they have full control of the system the can opt to do things like that. Pretty sure it is doing more than just decompression… anyway I wouldn’t be supprised if it could handle things like moving entire regions into memory as needed and it knows when they are needed etc… or can be programmed to know. So instead of having mere prediction in the IO controller you can have fully scheduled IO. Anyway just guessing a bit there but… seems like is what you’d want from a coprocessor designed to stream textures to a GPU.
Uh, the NVMe interface is, almost quite literally, “hey, move this here,” with of course different queues and stuff like that on top of it. How are you going to simplify that interface any more? I mean, you can put any number of chips between the CPU and the SSD, but you have to account for all the same stuff that the NVMe interface accounts for.
And no matter what you offload, the CPU has to get it and unblock eventually, so there are two ways it can be notified: it polls for it, or it gets an interrupt. So again, another chip does not help here, you have just moved the problem to a different interface.
“Moving entire regions into memory as needed” is what the file cache is for. A dedicated chip will not help you: the CPU still needs to know when things are done and then do something as a result. So again, interrupts.
Do these consoles actually have separate GPU and CPU memory? It’s pretty common for consoles to have unified memory to save that copy time, in which case sending textures “direct to the GPU” is moot, because they are going to the same place as if they are going to the CPU. And somewhere there are answers, so I’m not sure why you need to guess.
It’s unified memory indeed, wierdly MS’s Xbox series X has asymmetric bandwidth though even though it is unified memory.
PS5 just has a big single bus of GDDR6.
Think of it this way… AMD’s SSG card, that’s the first place the did anything like this, basically the took a GPU + PLX chip + SSD on the same card. And the GPU could memory map anything on the SSD basically. The SSD was just a normal SSD from the OS perspective also just behind a PLX chip.
This takes that a step further and moves the control of when things get moved back and forth out of the driver/OS/main CPU and moves it into a coprocessor… advantage being you can build something small just to do that thus saving die space and power. Also HBCC touted some ability to move things back and forth based on your typical cache methods scoreboarding etc… or something like that but it was predominately controlled in the driver, for instance the RoCm drivers have some support for it but it is effectively just virtual memory for OpenCL and nothing more, all the smarts were in the driver.
I think what they are doing on PS5 is they have an IO controller that profiles each frame determines when mapped pages are needed during a frame from the SSD before the GPU even needs them, so it can predictively load based on the last frame so you have zero latency intra frame streaming from the SSD rather than on demand loading. The big sram is not so much cache as it is profiling data for the IO controllers. All the CPU ends up doing is telling the IO controller if data is going to be used or not so for instance if your game engines knows a texture is offscreen it could unmap the texture and potentially spill any profiling data to ram. Interestingly Zen 3 or 4 will likely be able to spill the micro-opcache to ram… as AMD released a patent on this recently.
Anyway all of that reduces how much you have to keep loaded during each stage of a frame, and may let you plan access patterns around GPU bandwidth usage.
Apparently “Sampler Feedback Streaming” is now part of DX12Ultimate (aka DX13 but we can’t call it that), It’s something that requires a hardware access profiler to be fast otherwise it would already be done today.
Also I think it is not so much about making it nessicarily faster they could have made one of the big zen cores do this and attach all the decomrpession/coherencey/dma hardware to it… but there is alot of stuff in a zen core you don’t need for this task so they didn’t for the PS5, while MS kind of did also they wen’t with a more conventional cache.
Also the conherency stuff is why more important than you’d think… since it is now able to prevent cache flushes by scrubbing memory instead of flushing (even Navi flushes a times). Which results in a significant percentage of bandwidth usage improvement.
Just one note: Linux usually optimizes things for servers and other “big iron” machines that do lots of processing. Our use cases are different and this is the reason we believe it is worth developping our own Kernel. I would think this is one such case: when you’re on a server maybe it doesn’t matter much if one of your 128 cores is a bit more busy than usual, but it really matters that your IO is really as fast as it can be. On the other hand, when you’re on a laptop, you have maybe “only” 4 or 8 CPU cores, and powersaving is more important than extremely low latency.
Also, 1ms is a very long time for a CPU. At 1GHz, that’s 1 million clock cycles. At 3GHz or more of modern CPUs, that’s even more. You can probably schedule and run a few dozen threads without any problems. I would maybe consider polling for things that take maybe a hundred microseconds, but certainly not more than that.
Just to clarify, do you mean this purely in the context of I/O? Asking since Haiku runs in a low-latency mode by default and it seemed to me both from noticing this and using it, avoiding high latency in general as much as possible is a goal for the OS.
I don’t mean this in an extreme way that we would always focus on powersaving at all costs. Just that we set the cursor differently from Linux, and in this particular case, a bit more on the powersaving side.
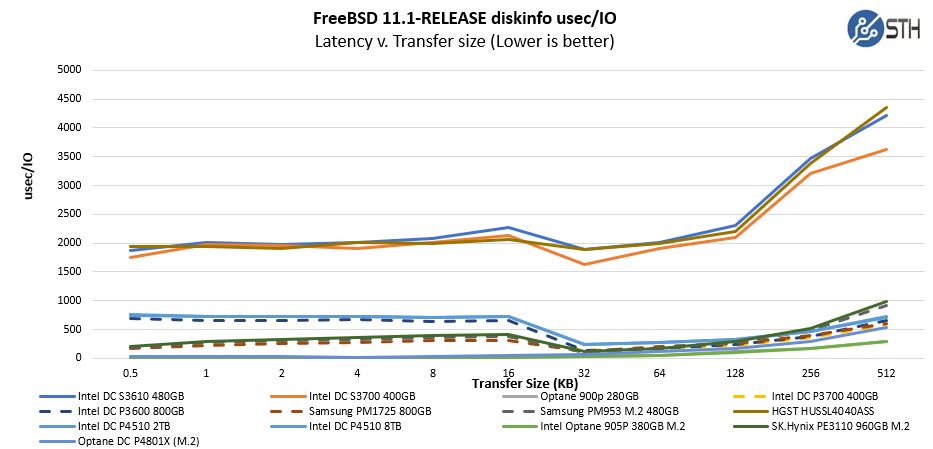
And yes some of these are server drives, but not all… the lowest one on the graph in fact is a 905p a “consumer” drive and Samsung drives can get down into those ranges also.
Actually, even under emulated NVMe, I think I observed have only seen one I/O stall: the one when the drive cache is flushed at the end of the BFS log, which is slow because it is emulated and under a spinning HDD. But I guess I did not comment that out so I don’t really know if that is indeed the only problem. The latency is much better anyway.
I also note that the iterative I/O bug I fixed yesterday would double-write/double-read in cases where it was not needed (or would corrupt the disk), which may contribute to the saturation problems.
{kind=link}