Hi again!
Congrats on getting selected in Gsoc this year. I am planning to implement write support for btrfs as I have been focusing on this over the past few weeks.
I have read the blogs of Hy Che (2017) and brj (2019) who started the write support feature and I’ve pointed things which are not implemented yet.
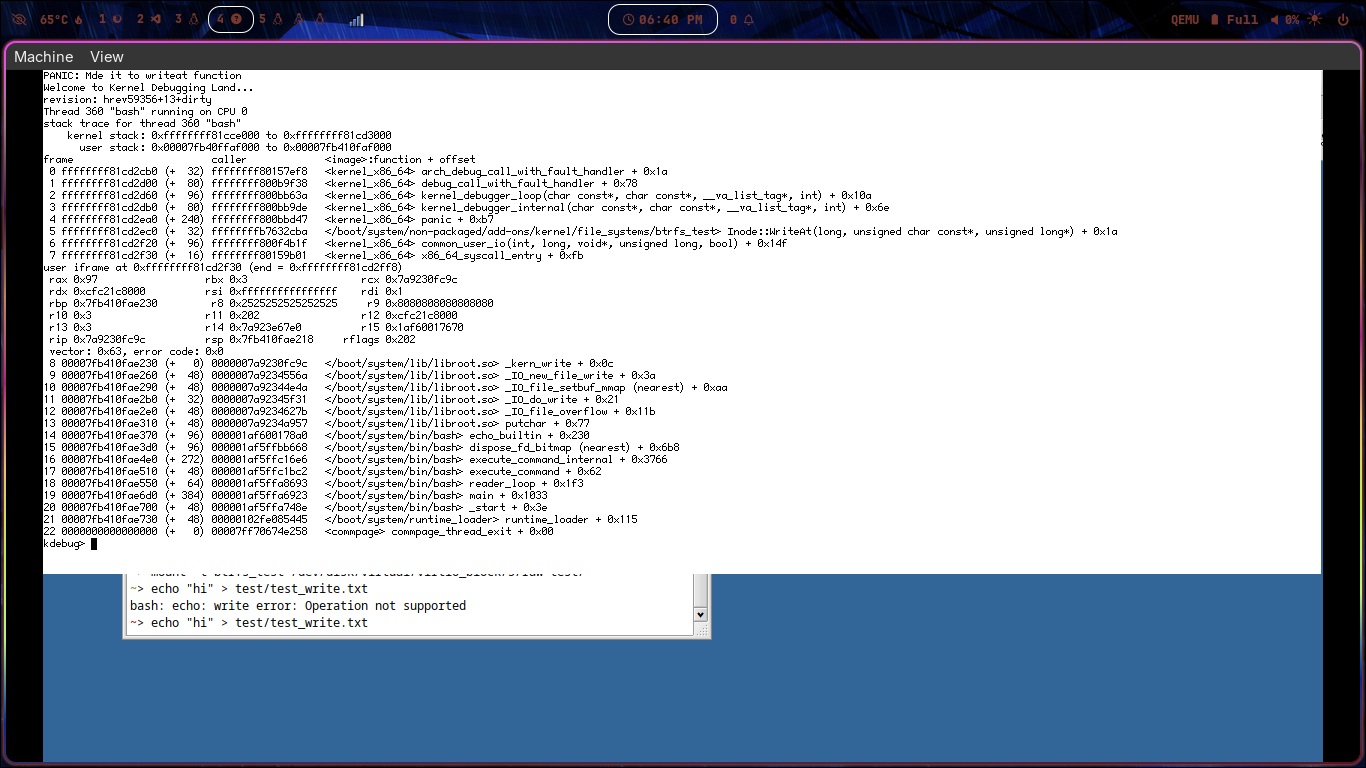
I wrote a new function in inode.cpp ( writeAt ). In kernel_interface.cpp, updated btrfs_write( ) to return this new function instead of B_NOT_SUPPORTED. Also return B_OK when file needs to be shrinked/grow in btrfs_write_stat() function. In Volume.cpp, I noticed the Mount function sets flag to Read only and there is extent allocator crash when mount is finished. For the time being I bypassed these things, just to test if trying to write actually hits the writeAt( ). And it worked. (screenshot attached below)
Also thanks for giving tips to improve testing in my last post. It worked and by renaming my test module I can now test without rebooting the VM.
Now regarding btrfs, I want to understand it now so that the coding period of GSoC won’t be wasted in basic research of the topic. Any tips or guide is highly appreciated.
They won’t help you with the Haiku code, but they can help you with questions related to the filesystem structure on disk and the algorithms needed for write support.
Ok so I wanna share some updates about my preparation.
I have read On-Disk Format, B-Tree Architectures from Btrfs documentation ,as suggested, to have an idea of how it actually works.
Besides this I went through https://github.com/torvalds/linux/blob/master/fs/btrfs/file.c to understand how they have implemented the write support for btrfs. Here is what I understood from this:
any write operation → btrfs checks if disk is healthy → lock the file → chop data into smaller chunks → one chunk is considered at a time → physical & metadata blocks sizes are calculated and locked → copy data in RAM pages → label that sector as “dirty” → an OS thread permanently saves it in hard drive → transaction starts to ensure no corruption → btrfs write data in the disk without removing old data → old pointer is shrinked, new pointer points to new leaf → B-tree update and transaction is committed.
Now my next approach is to map this implementation in haiku code(function names, and roles).
Is there something I should focus on more deeply before I proceed?
Btrfs is based on “copy on write” mechanisms. As you wrote, this is achieved by redirecting “pointers” to the new data, but it also means the old data has to be garbage collected and released to free space when it is not reachable anymore.
I don’t know how btrfs manages that, but it should likely be taken into account, even if it is not directly a part of the write process. Otherwise, the disk will quickly end up filled with old, unused bits of data that are not connected to anything.
On Haiku side, you may want to look into our own caching system, which is made of two parts: file cache and block cache. To determine how this should fit with btrfs operations. Does our existing code already uses the cache for read operations? It’s possible to write an entire filesystem without using the caches, but then all operations will run directly on the disk data, which means a lot of read and write access. With the cache, a lot more of the operations are done entirely in RAM, and flushed to disk only a little later. Usually this means the changes can also be batched and the impact on performance (and possibly also on not wearing out the disk too much) is quite high.
You can also start thinking about the scope of the project. btrfs supports several advanced features (snapshots, for example). It’s likely not possible to get it all implemented over the course of one GSoC project. So, where can you easily stop? Is it possible to do a write implementation without snapshots/reflinks? What if we mount a filesystem that contains such things, and try to write to a snapshotted/reflinked file. Do the write algorithm already make sure that this will not corrupt other versions of the file? (I think so from your brief description, but it is a thing you can explain in your GSoC application)
Do other features also have implications (for example, compressed files come to mind)?
Linux code uses reference counting for garbage collection. When we over write a file, old pointer is dropped, and Extent tree decrements the block reference count by 1. If count==0, space is marked as free.
Yes, actually I worked with cache system of btrfs read system. In my last commit (zstd decompression for regular extents), waddlesplash told me to use file_cache_read and btrfs_read_pages (called by file_cache_read).
Yes this is. In linux code, I read, they use functions like btrfs_check_nocow_loc (and snapshot_lock) to optimize writes by trying to overwrite in-place when possible. For haiku implementation if we use CoW for every write, the algorithm decrement the old block reference by 1. If file has no snapshot, block count drops to 0 (freed). If it has snapshot, block count drops to 1 (preserved).
Writing compressed files will be complicated enough. Linux uses completely separate code paths to implement it. For the GSoC, I think it should be out of scope, but surely if there is time or even after GSoC ends, I’ll surely continue contributing to it.
Regarding Project scope, it is large. There will be summer vacations during the coding tenure, so I’ll give most of time to the project. But, for exact scope, I’ll let you know soon after some research. Thanks!
So I guess it will return an error code if you try to write to an existing compressed file? It could also convert it to uncompressed, but that also looks like a lot of work for little gain, so just returning an error should be fine.
Now I have a more clear picture what has been done and what is remaining.
Some important things from blog that can help me are:
Both used fs_shell for testing.
Hy Che in 2017 completed directory creation.
btrfs_path: an array that remembers exactly which nodes you touched on the way down, keeping them locked in memory so you can safely modify them later. You will use the
btrfs_path structure he created to insert your new file extents.
cache_extent: This is used to keep track of chunks of data in RAM (like free space on the disk or blocks you are about to write) before actually writing them to the physical platter.
block_cache is used for metadata while for file data we have file_cache
For CoW to work, Hy Che built a “first fit” allocator
To prevent B-Tree overflowing he discussed node splitting and merging(Todo)
In btrfs, metadata is in node(tree block) while file data is in extent
Transactions: There are already functions to handle it, so I’ve to wrap the logic in it
To easily find node, there is Traverse() and GetEntry() function
@brj expanded metadata layer and implemented empty creation of new files (touch command)
Concept of inline and regular files.
These things are from blogs of 2017 and 2019. There might be some things done after that but I have to look it up. Now these things are to be done as stated in both blogs:
In scope:
Implementing btrfs_write as currently it returns B_NOT_SUPPORTED. Routing the function through file_cache.
Connecting file_cache to extent allocator. The btrfs_write_pages in gBtrfsVnodeOps is set to null. Implementing it will help me trigger the allocator.
CoW physical block allocation
Verify/Fix B-Tree node splitting and merging.
Implementing Write locks
Validation for cross OS compatibility
Stress testing
Out of scope:
Implementing compressed extents
Creating snapshots
In-Place overwrite (nocow)
Dynamic scaling of block allocator when disk reach max capacity
In scope will be done in coding period. If time allows out of scope will be done too, but if no then it will be completed after it.
Are there any suggestions among these or something else I should know?
It looks fine to me. If things go according to plan, you will have basic writing implemented at the end, and you can start testing with the filesystem in a real Haiku install (outside of bfs_shell). Then you will be able to run performance tests (for example bonnie++) and #unctional tests (xfstest) that will let you know where to look next (missing features or performance problems to look into). Some cross-testing with Linux’s implementation of btrfs (making sure both OS agree on the content of the disk and files) is also a good idea.
Thanks! I’ll make sure to perform functional & stress testing after implementing write support. As of now I’ll focus on drafting weekly plan for this project.
I do have a small question. Haiku Contributor Guideline states to submit an alternate proposal to give mentors "flexibility”. Given that, would you recommend me submit a secondary smaller proposal or should I focus completely on my current btrfs proposal?
This is in case there are multiple people applying for the same project idea. We can only accept one of them (as having two people work on the same thing will likely result in stepping on each other’s toes).
So far I have not seen anyone else interested in btrfs, so you should be fine. There are two other “filesystem write support” projects but they are both for different filesystems (XFS and exfat).
Hello!
Its been a while. Over the past few days I focused on initial draft of proposal. While writing it, I found more and more things. Like reading a forum thread of 2024 about same project proposal for GSoC, @X512 said about data loss in btrfs even on linux. I spent a considerable amount of time researching Haiku’s transaction API to architect a solution that avoids these exact pitfalls, and I have detailed this in the document. There were many other things I found after reading other files in btrfs/ directory which helped me in finding accurate path. I have attached the doc file link of proposal. Would love to hear suggestions and improvements
As you noted, you will start with btrfs_shell, but if you want to run more interesting workloads you will at some point need to run Haiku (natively or in a VM) and mount a filesystem in the OS “for real”. It’s something you can start experimenting with now and until the community bonding period, just to make sure at least the existing read support is behaving well.
I also noticed that there is an old patch to implement btrfs_create: https://review.haiku-os.org/c/haiku/+/1531 maybe you can adopt it and see if you can reply to some of the questions in the existing review comments. I think it should allow to create empty files, but not yet write to them?
Maybe your proposal can also include a review of the other unimplemented hooks. A few more than “write” are needed, and some of them may be easier to implement first (for example: rename, link, maybe write_stat). Some may be out of scope or may not be needed at all, but mentioning them and explaining their status in the proposal would make it even more complete.
I’ve never had any failures on BTRFS. I never lost any data using BTRFS. The author of EXT4 recommends using BTRFS, not EXT4.
The problem that scares almost everyone, is that RAID5/6 has a write-hole issue, which causes data loss. If they had read the documentation, it says something like: “Experimental, only use for testing”.
-If you want a rock solid BTRFS, just disable the possibility for the user to use RAID5/6.
I experienced issues with BtrFS corruption multiple times in Linux and also native Windows driver. Also unlike other file systems, there are no good tools for BtrFS corruption recovery. It seems BtrFS authors recommend to fully reformat and restore volume from backup on any kind of corruption, even small one, that is not practical for desktop use. Even Haiku native BFS is more stable to my experience.
Maybe it is some kind of hardware failure, who knows. But BFS and NTFS works fine on the same hardware.
I’m sorry to hear that. This is actually first time I’ve heard anyone saying BTRFS not being stable. One thing I must point out, is that drives (both SSD and harddisks) should be switched out after 10 years; I don’t know if that was the cause of the problems. If you’re using RAID1+0 like I am now, then it doesn’t matter much if your drives are old, though. Personally I purchase WD RED; I haven’t seen a failure on those yet either (started buyin WD RED back in 2012).
Do you have an idea of the cause of the data-corruption (I’m just curious here) ?
Maybe some broken sector. Other file systems such as NTFS are more resistant to hardware failures, it even have bad block map structure. BtrFS switch to read-only mode even on smallest corruption if I understand correctly. Also copy on write increase SSD wearing.
I had experience of Windows XP running on dying clicking HDD formatted to NTFS and sometimes failing to boot. It managed to stay that way for several months until disk was replaced. That demonstrates how excellently NTFS handle hardware failures.