A kind good afternoon to all of you,
I’m creating an utility with Haiku-PyAPI to compress and decompress files and folders in a tar.bz2 format with a parallelized bz2 compression. This utility will specifically target the Haiku system not only for its interface (obviously using Haiku-PyAPI) but because it will add BFS specific attributes to the compressed files, and restore them at decompression time.
but now I am thinking about endianness…
If I compress a BFS file attribute in a little endian machine as mine (ours) and then moving to a big endian machine, will it be decompressed correctly? For example: if I pack a double precision float attribute in little-endian bytes, on the big-endian machine to unpack it correctly, do I need to unpack the byte with the original endianness, recreate the byte with the correct endianness (big) and then BNode.WriteAttr to the filesystem? so summing up, does the BFS attributes on disk follow the machine endianness? Am I only blathering without sense?
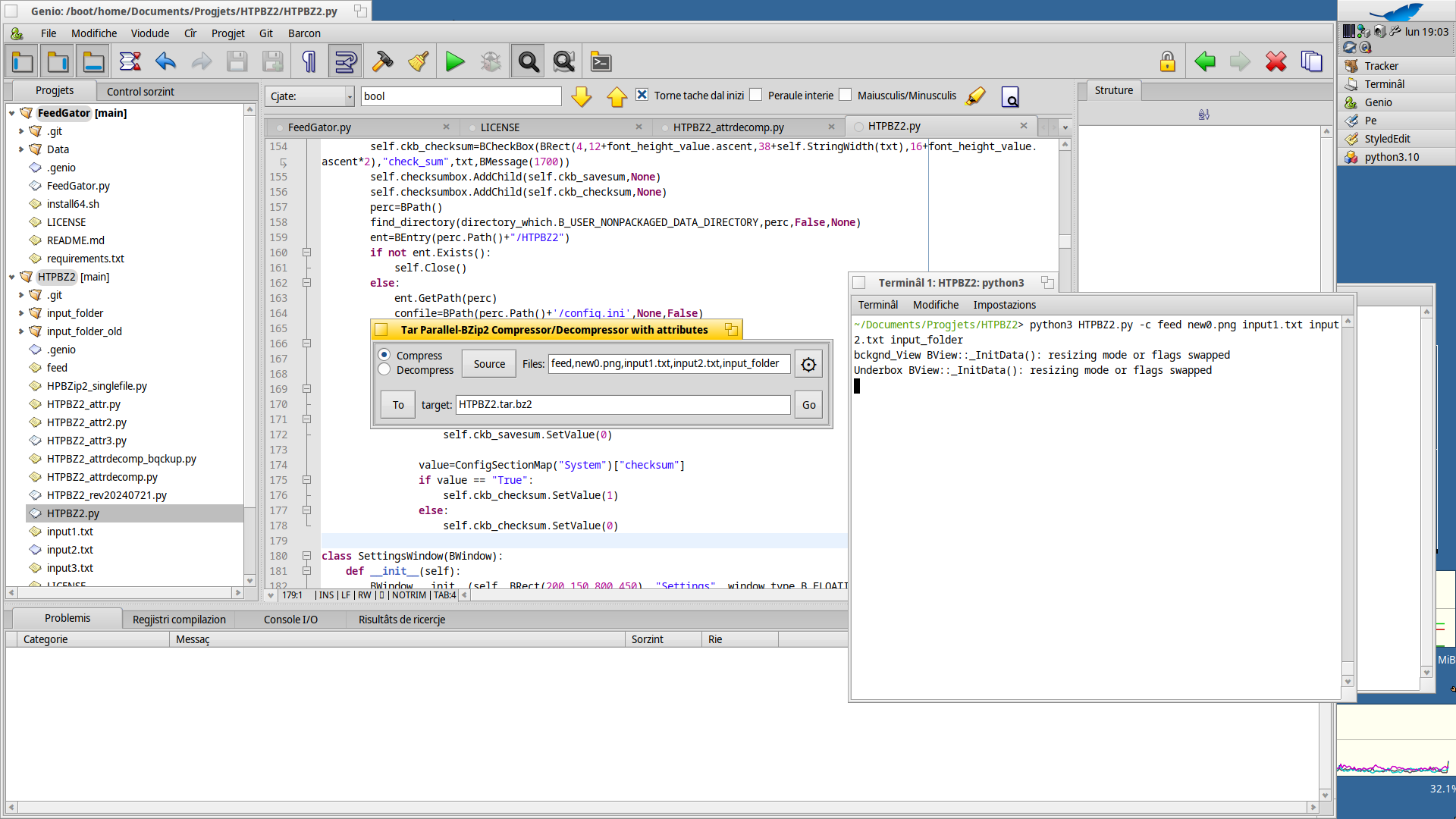
that’s cool, but do you need to specify the files in such an inconvinient way when it’s finished or are you planning to expand on it?
Generally I suggest to have a proper serialisation/deserialisation step. So not storing the raw data as they are on the filesystem but some format that is independent on things like endianness.
For example for numbers it is often easer to just store them as strings (ASCII decimal) than to store them as binary numbers.
Also given that you compress/decompress the stream I wouldn’t think that this has any impact: serialisation/deserialisation overhead is likely small compared to compression overhead, plus compression will also reduce the size of your structure again (if one is worried about that to begin with).
Btw. I’m also interested in knowing how you add the metadata to the archive. So if you share your code at some point let us know. ![]()
Perhaps you could skip all of the attribute handling and let the tool handle it. Both GNU tar and bsdtar have xattr support. At the moment they both have limitations on the size of attributes, however, the libarchive/bsdtar developers have recently removed the attribute size restrictions for the pax/tar format. I have not tested it yet but it should be as capable as the zip format for storing BFS metadata.
Mmh not sure what you are talking about, can you develop a little more this subject?
Actually the attributes are read through BNode.ReadAttr, and saved in a json-data, so at compression time:
- int-like attributes are effectively converted to strings
- string-like attributes are saved as they are
- byte-like attributes like RAWT and MSGG etv. are base64-encoded
- same happens to float and double which are converted to bytes and encoded with bas64
- bools are struct.packed and decoded as utf-8
- everything else is serialized as RAWT
on decompression time:
- RAWT bytes-like data is base64-decoded then written as is with BNode.WriteAttr
- same for Float and Double which were already converted in bytes at compression time (WriteAttr asks for a byte object)
- strings are encoded to bytes
- ints (previously saved in strings) are converted to int, then converted in bytes
- bools are reconverted in byte
more or less this is my attribute-saving way
This is very interesting, but also means that I should throw away all of my code ![]()
sorry, worded it badly. What I mean is if when it’s finish it is more viewable which files you selected. instead on it being shown in one string
Well, still have to finish that part, anyway input files can be passed as ArgvReceived (through command line or passed by my c++ wrapper which can be addressed as default app through FileTypes) or can be selected through FilePanel selection. That “single string” is just a memo you have already selected the files to compress/decompress, it can be written “by hand”, but it’s not intended as primary method.
For now the only working method is through App.ArgvReceived method
This is in alpha state.
Still have to add optional checksums checks
here’s the link if you wanna take a look.
Just remember that if you want to run it you need to compile latest Haiku-PyAPI, due to some recent fixes. (a hint, if you want to clone the repo write this command:
git clone --recurse-submodules https://github.com/coolcoder613eb/Haiku-PyAPI)