I’m very glad to see so many positive and encouraging responses! Thanks guys, that means a lot to me right now.
I’ve updated the announcement to include a screenshot and some links to the datacentric manifesto and also to my fork of Haiku for necessary changes to Tracker (I’ve been developing in Java and more recently Kotlin in the last 20 years so please ignore my rusty C++…).
Let me answer to all questions in one sweep:
@Munchausen: no video yet, need to brush up the prototype some more to make it also more telling and understandable.
@Nexus-6: you get the idea. I am also an avid supporter of Zettelkasten, however not as strict as the original concept, but more flexible in the way of Atomic Notes or a “Second Brain”.
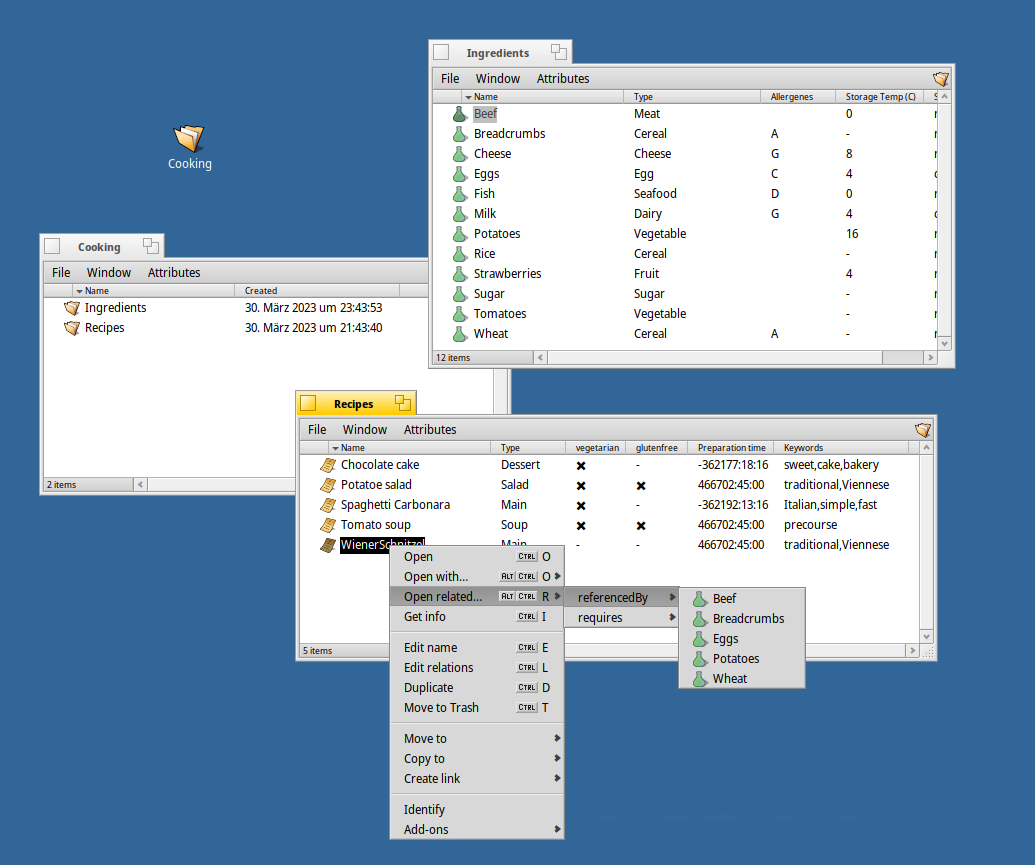
SEN is just a tiny core that enables applications to resolve relations using the SENPAI (SEN Programmatic Application Interface:^).
But the gist is still to offer users a simple way to do much information handling in Tracker, without the need for separate applications. Tracker is already more than a file manager, since even BeOS had e-mail “files” that were actually entities with their metadata extracted into filesystem attributes.
With such a concept, there is no need for writing simple CRUD applications just to manage all possible kinds of data (think entities) like movies, books or even recipes. This can all be handled via files and the underlying entity relations in Tracker, with careful extensions and adaptations.
If you follow that path, you get a simple but very powerful system to manage your information in a connected way, still using specialised applications where needed.
For this to work however, we need to free data from the control of applications. Even with open data formats, users still rely on a handful of applications can handle them, when they often just need to access basic metadata - this should not be necessary.
E.g., a PDF document has all kind of metadata hidden away, like keywords, author, page count etc. This should be extracted into attributes, sothat users and applications can work with them in a more generic way (think horizontal connections, not vertical ones that really need a deeper understanding of the content format, e.g. word processors).
As for linking, this is already baked into SEN, using relation properties like offset, page number etc. I call this “SENCHA” (SEN Context Highlighting and Annotations:^). When you open a relation in Tracker, SEN will intercept and open the preferred application, moving to the relation target context. This would allow you to follow a relation from a book note or PDF annotation stored as text file to the original document. Of course, the target application needs to support this in some way, e.g. scripting message in BePDF to jump to a page and highlight a part of the text. This is very much resembled in WebAnnotations now, and could be handled the same way in Haiku, where locally stored WebAnnotations would allow you to jump to the web page and highlight the text - great for research, without the dependency on online services and subscriptions.
@PulkoMandy: thanks for your encouraging words! This means a lot to me, since I know you can be very critical and challenge ideas floating around here:)
@ubu: that’s my secret hope, really, however in a slightly different way: Haiku does not a single killer application, but a real enabler. Something that makes people wonder why they cannot do this with their current OS. I have thought a lot about (and heard from many people) how crazy it is to build this system on Haiku, but after some more research I found it was a very sane thing to do, as no other OS offers this powerful combination (e.g. you cannot search for custom attributes in any other filesystem, which is really astonishing).
I don’t know if SEN can ever be such an enabler, but it could make some people curious, and for me it is the easiest and most enjoyable way to build this solution:)