Hi!
I’m building a simple PO editor in python and Bethon, as before it runs only in 32 bit Haiku…
I know that Haiku software uses catkeys but I hope it will be useful in translations for other projects.
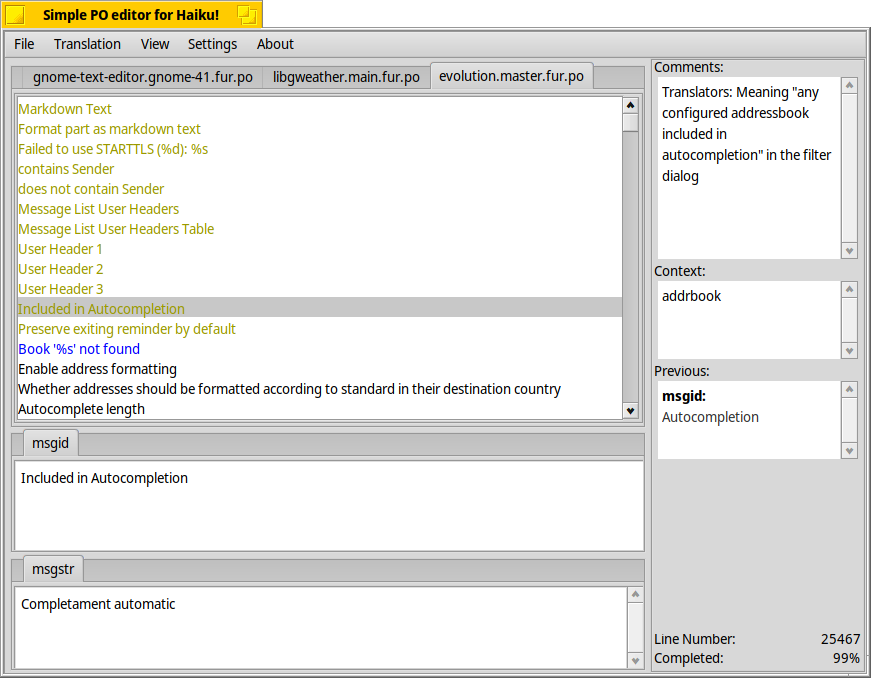
It’s in an early stage, but can do some basic operations
here some screenshots:
It’s a bad piece of software, not optimized, slow and maybe you’ll face some bugs… This is why I consider it in alpha state
Anyhow it seems to do its job.
I’ll add some features in the near future (like handling the header of pofiles)
Notice this:
In github repo I placed a zipped file with gettext mimetype to place in /boot/home/config/settings/mime_db/text
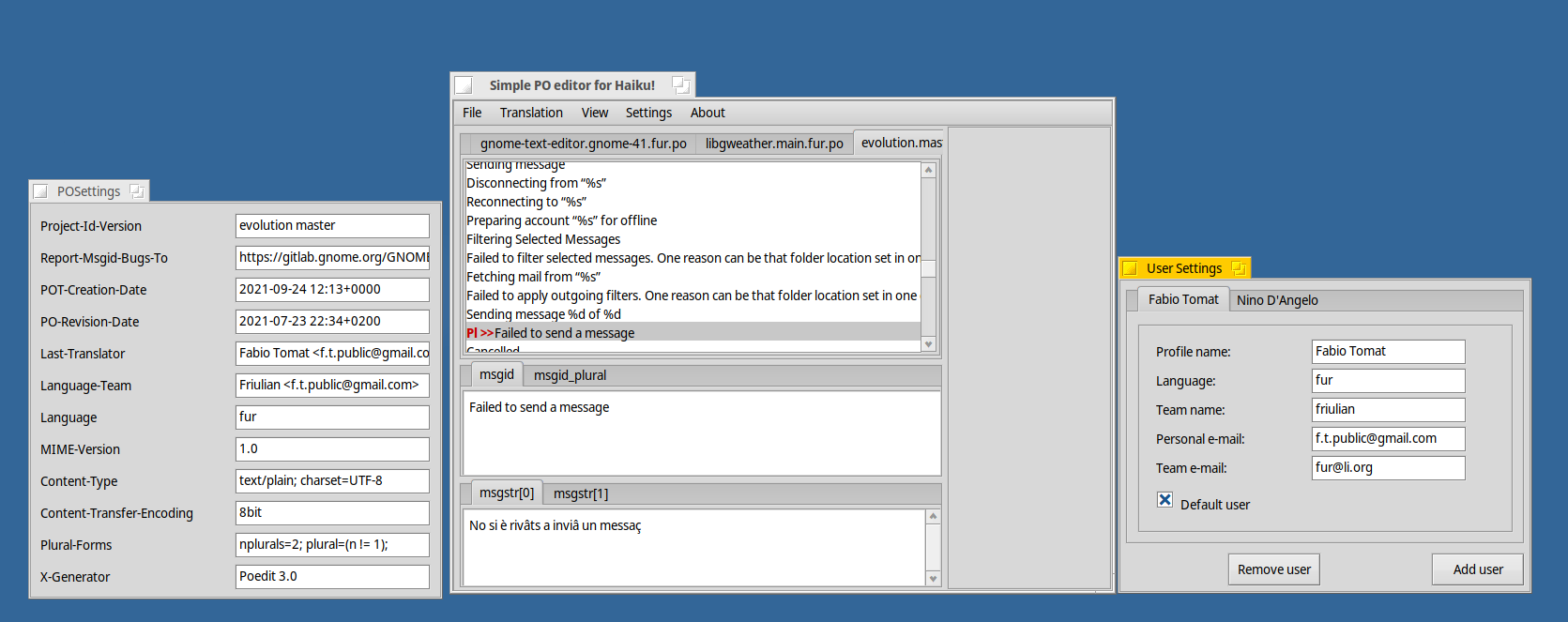
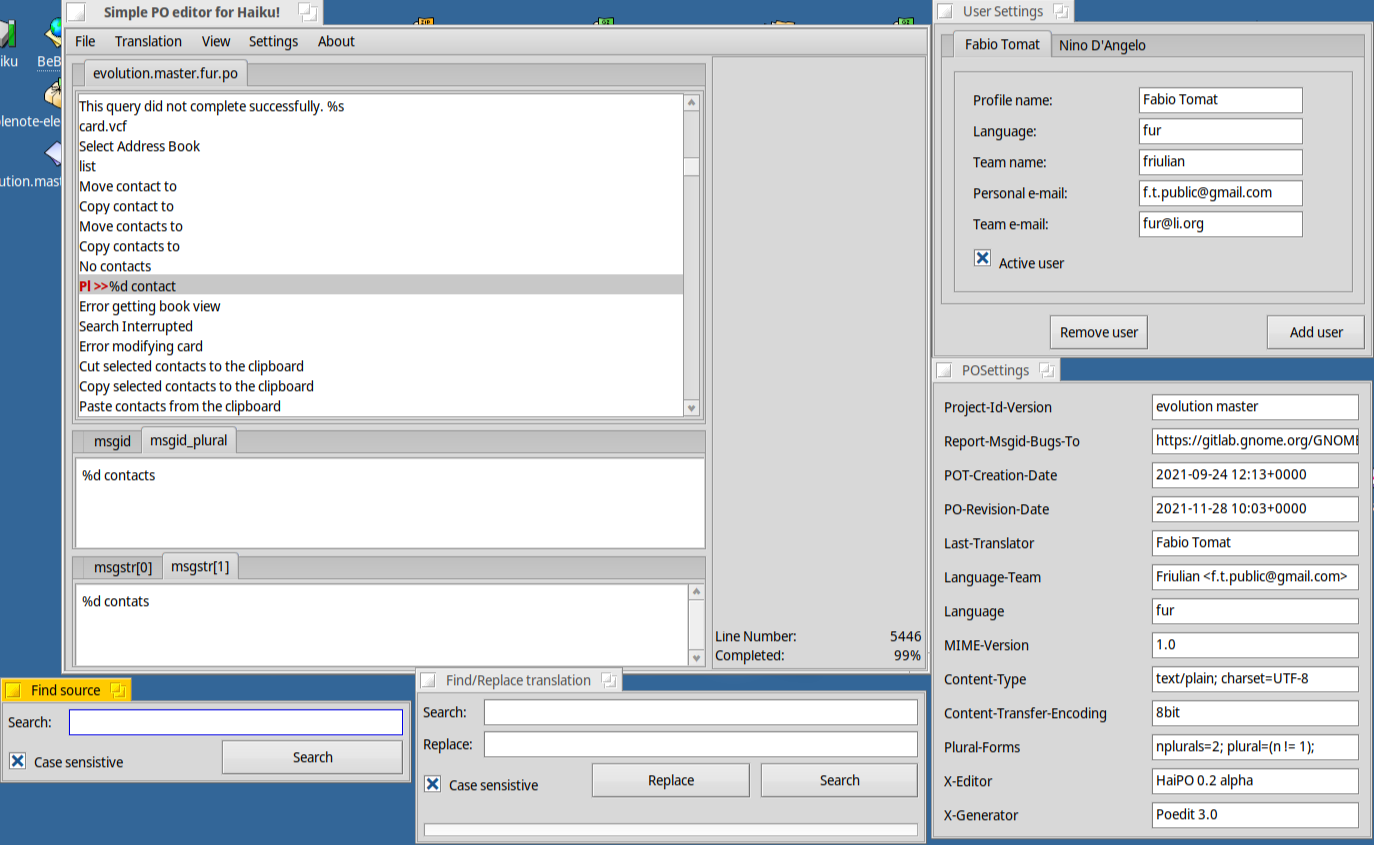
At first run it will create a user profile which will be saved in config.ini
Temporary changes will be saved on a file called normalfile.temp.po
Load of “big” files takes some time due to double checks for multiple occurrencies (one day I’ll rewrite the source code) for example a file with 5800 entries takes more or less 7.5 seconds to load on my Intel Icelake 1.2Ghz
To run this application you’ll need python, Bethon (which runs only on Haiku-32bit), and polib for python which you can install with pip command
Update:
An issue has been fixed and the workaround has been eliminated, i.e. now load-time of a file with 5800 entries takes 0,5 seconds on an older and slower machine (equipped with an Intel Pentium N3700 at 1.6GHz)
Well, some progress…
As there’s no hunspell integration for python 2
I did it the wrong and worst way: launch hunspell as command and decode the output.
As the output of hunspell counts the position as characters and not as byte I had to analyze the string and exclude some double bytes chars (I know that’s not good) so for my language I have to analyze including characters and excluding categories of characters (will be implemented in a configuration section)…
If I find a better solution I’ll do it later. For now it works for me and maybe for other languages… didn’t try…
But at least now I have what I need for my work.
(the spellcheck works only on some calls: typing and moving the list selection with CTRL+DOWN/UP/PGUP/PGDOWN)
I mainly just want to say, it made me smile, to randomly select a thread here and find that it’s about a Bethon project. With extra functions, which means someone figured out how that horrible apparatus works. Do you know why Bethon isn’t available on 64 bit? I don’t really know who’s supporting it these days - not me, for many years - and I suppose that’s likely the problem right there, but just wondering if there’s some real issue there.
Just tried to compile it on x86_64, it runs into typecasting errors where it is assumed that pointers are 32bit. These shouldn’t be too hard to fix but I don’t know if there are any other issues.
And it is still python2, right? We really need Haiku API bindings for python3 if we want to have python as a serious option for app development on Haiku.
Here I am, again…
Update: with the recent updates I introduced the support for an external Translation Memory.
Translation Memory explanation
For those who don’t know what a Translation Memory is: A translation memory (abbreviation: TM) is a database that stores “segments”, which can be sentences, paragraphs or sentence-like units that have previously been translated, in order to aid human translators. (cit. from wikipedia)
As a lot of modules are missing in Python2 (and in python3 under Haiku) I thought that it would be easier to rely on an external TM server.
So, as far as you respect a simple protocol, you can create your own (and probably faster) TM server. What I provide here is a simple python3 server that uses a TMX file (Translation Memory eXchange) for finding, adding and deleting your strings.
The TMXs files are easily generated with python3 translate-tools (po2tmx command); surely a SQL database is faster…
By requesting a string from the server you’ll get the 5 most similar translations, which can copied to the translation field by pressing ctrl+1+2+3+4+5 shorcuts (or by a double click).
By Pressing Canc/Del after selecting one suggestion, you’ll erase it from the TM server.
I’ve added a Launcher to use in FileTypes, so when a .po file receives a double-click it will be opened with HaiPO
I’ve update the x-gettext-translation filetype (you can install it with the install.sh script)
The journey:
Since I started this project I realize now that it starts to be more comfortable for my translation work. There’s still a lot of things to tune up, but I see that Haiku now is my preferred OS to get my (GNOME and TranslationProject) translations done.
A big Thank You to all Haiku Devs and to Haiku itself