As I’ve mentioned in a few previous updates, I’ve been working on replacing the malloc implementation in libroot. Currently it’s based on an aging version of hoard2; we tried to replace it in the past with mixed results and the replacement wound up getting reverted.
Well, now (after a lot of work on the kernel VM core itself), I have a new prototype replacement, this time based on OpenBSD’s malloc. However, I’ve added a process-global caching layer beneath it to improve performance and align better with Haiku’s APIs.
The result has slightly faster performance than the old malloc in some single-threaded benchmarks, but the really big advantages should come from applications with high memory usage (100MB or more) as well as long-running applications, both of which should see significant performance improvements as well as significant memory usage reduction.
I’ve been testing it myself and haven’t encountered any really big regressions so far. There are some test builds available from @madmax’s server at the moment, if a few people want to try and experiment with them and see how things seem for you, that would be great. Just use the system normally and see what happens.EDIT: Test builds removed; thanks everyone who tried them!
I still have some more TODOs to investigate before this can be merged (e.g. unexpectedly higher memory usage in some applications; by a few MB at most but this probably shouldn’t be the case) as well as validating the cache logic. But this is getting pretty close to something that’s ready to be merged.
Any particular reason malloc from OpenBSD is used? A quick search brought up interesting things like SuperMalloc and xmalloc, which seem to be fast(er)?
Engineering is always a compromise. Haiku is heavily multithreaded, and what works well for a single thread may have regressions with multiple threads. Augustin mentioned a previous attempt, that was rmalloc (from memory), and that proved very problematic with gigantic allocations (eg. Medo 4k video cache, 32Mb per frame, 960Mb per second of cached video per track). Rmalloc worked fine for smaller benchmarks but died with Medo after 10 seconds. The old hoard2 was at least stable.
I don’t know, it depends why they’re slow. Only one way to find out, I guess! Let us know how it goes, if you do test it.
Yes, I tested a fair bit with Iceweasel myself, it seems to still work fine.
There are many, many different mallocs with many different implementations and thus performance/usage tradeoffs. Having been burned before, my requirement this time around was to choose from the existing mallocs that had already seen significant use as malloc implementations within a libc. This left a much smaller set to pick from (ptmalloc2, jemalloc, musl mallocng, etc.)
Previously I’d tried musl mallocng but its performance just seemed too poor in multithreaded usage. The OpenBSD malloc on the other hand has performance that’s much closer to our existing malloc while having a lot fewer shortcomings (plus it has some nice facilities to detect memory problems without impacting performance too much that we might turn on in the future, at least on nightly builds.)
Applications which can benefit very significantly from a more specialized allocator design should probably just use a specialized allocator. Already compilers (GCC, clang, etc.) do this, as do other high-performance applications and libraries.
“rpmalloc”, but yes. Any chance you could give this a go with Medo and see how memory usage looks?
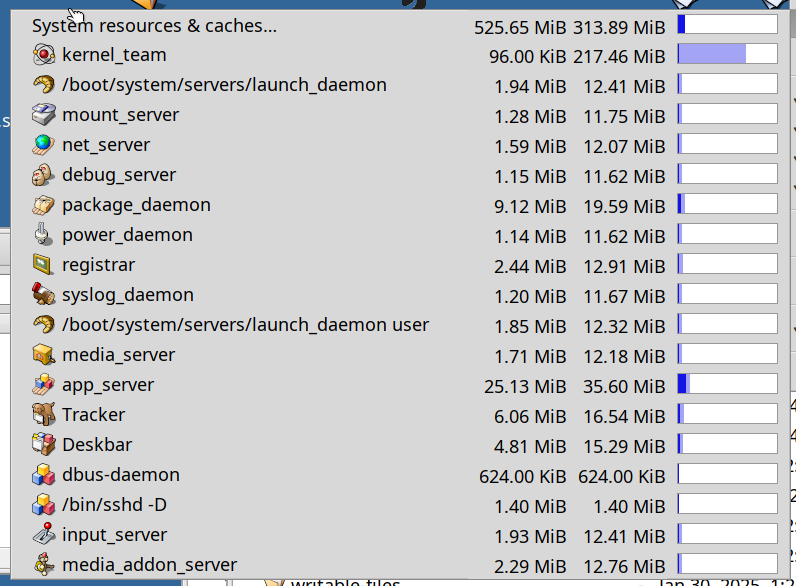
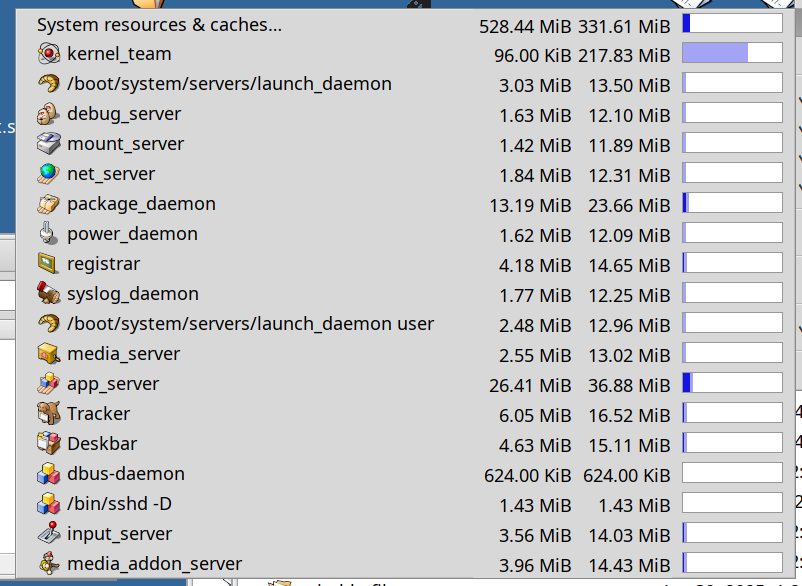
So, a little higher, but not too much (total usage around 318 MB → 334 MB.) I have a few optimizations in various applications in mind that might bring this down a bit, but on the whole this appears to mostly be due to actual differences in allocator behavior.
I dug in a bit to registrar in particular (which went from 2.44 MB to 4.18 MB as you can see in the screenshots), and it turns out registrar has very heavy and complex allocator usage: booting to desktop and then letting it sit idle for a handful of seconds, we get almost 60,000 calls to memory allocation routines in the registrar, with lots of overlapping malloc/realloc/free. The only way I could manage to get the memory usage to actually go down here was reducing the amount that the allocator “maps ahead”, but that would almost certainly have a disparate impact on performance.
So in the end I think an overall ~5% system memory usage increase (though that’s counting the kernel memory usage also, which is unaffected by these changes) isn’t so bad for the other benefits this brings. Especially considering all the memory usage optimizations that have happened since beta5.
They tend to have well-written and well-used code, so what’s not to like?
But it’s not seen much usage as a libc allocator, from what I can tell. There is one up-and-coming Linux distribution (“Chimera Linux”) which intends to ship with it, but they haven’t fully launched yet (and I don’t know how many users they actually have.)
Besides the fact that it hasn’t seen extensive usage as a libc allocator like the OpenBSD one has, its primary mechanism of committing/decommitting memory requires the kernel to maintain per-page protection information. This will increase the kernel’s memory usage (4 bits per page, whether the page is actually used or not) and is a performance hit for page faults (since we have to check the per-page information), fork() (since we have to re-protect pages individually rather than as a group, and we also have to allocate and copy the page protections arrays), and decommitting/unmapping (since when cutting areas we must resize/reallocate/copy the page protections arrays.) That seems like a significant disadvantage.
The performance differences on a build job were within the realm of noise (I got results of around 29.2s for the OpenBSD malloc and 29.6s for mimalloc – though the mimalloc sys time was consistently higher, it was around 12-13s vs. OpenBSD at ~10s.) On some applications like the Debugger benchmark it was faster (the benchmark ran at around 1.7s-1.8s instead of 2.3 or 3.0+s), admittedly.
One thing I didn’t check until now was relative memory usage. It appears mimalloc does use less memory than either hoard2 or OpenBSD (in terms of actual pages used, not commitments/reservations, where I expect it uses much more), and not by a small amount either, but double-digit percentages or more in many cases. Maybe it’s worth revisiting then; but at least in my testing the system crashed after not too long with this in the syslog:
0xffffffff994c8d98->VMAnonymousCache::_Commit(1073741824): Failed to reserve 1073741824 bytes of RAM
low resource memory: note -> normal
debug_server: Thread 3885 entered the debugger: Segment violation
stack trace, current PC 0x1c2f5936d3b </boot/system/non-packaged/lib/libroot.so> mi_thread_init + 0x2b:
(0x7feea61bd100) 0x1c2f58a94d2 </boot/system/non-packaged/lib/libroot.so> thread_entry + 0x12
i.e. it looks like it tried to reserve 1GB RAM on thread entry, and then crashed when it failed to do so. So it appears the commitment behavior here is still not great. If we can manage to make it behave more sanely here (and maybe avoid per-page protections at all), then perhaps it’s a contender again.
Yeah, I just looked at this some more. With mimalloc, the used pages is less, but just after boot the reserved memory is ~1GB (out of 4GB on this VM) instead of ~300MB (with hoard2) or ~330MB (with OpenBSD malloc). That’s obviously much worse.
Solving that may not be easy depending on allocator behavior. But the savings are so large with applications like web browsers and the like that it indeed makes sense to spend time looking into it, I guess.
Hmm, maybe in the end it doesn’t actually save so much memory, and this is just a bug in ProcessController. I see that the general heap area is using 0x1798000 bytes (~24MB), but ProcessController claims only 3.77MB are used. So that seems quite wrong.
EDIT: Found the problem, due to how memory protections work they weren’t getting accounted properly. In the end mimalloc has similar memory usage to OpenBSD, maybe a little lower in system services on startup.
I tested starting Iceweasel, letting it load the Google homepage, and then closing the browser immediately when the tab flash for “loading complete” occurred. mimalloc: ~5.3s, OpenBSD: ~5.8s, hoard2: ~6.5s.
Obviously this is a rather “unscientific” test because it depends on user input (and network latencies), and an 0.3-0.5s difference due to that makes a big difference in the results. But at least this seems to show that the OpenBSD malloc is not so far behind mimalloc and it is certainly better than hoard.
I think on the whole the OpenBSD tradeoffs are good enough for use in Haiku as the default allocator. We can and should enable other allocators for applications like web browsers, though (Firefox uses jemalloc on most platforms, we could port that as well since it’s what Firefox/Gecko are most tested with in the end.)