Yeah! B_MOVE_DISPLAY is working with radeon_hd and my patch. Tested on RISC-V board.
ScreenConsumer should start work after proper implementing clone accelerant.
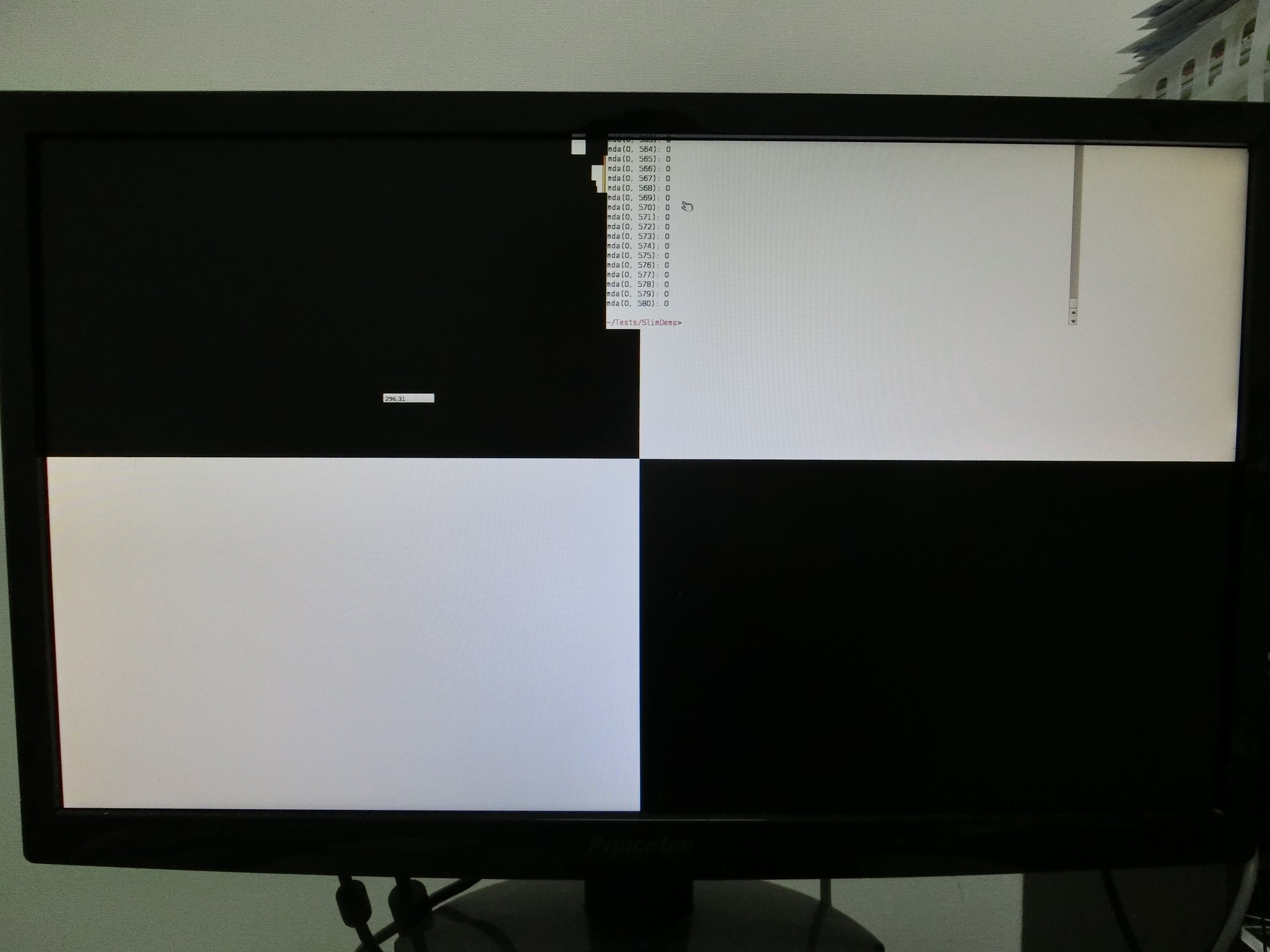
Yeah! B_MOVE_DISPLAY is working with radeon_hd and my patch. Tested on RISC-V board.
ScreenConsumer should start work after proper implementing clone accelerant.