There’s also The Haiku Book: Introduction to the Layout API. We should probably migrate the docs on the website into the Haiku Book, as they’re easy to miss…
1 Like
I agree with you on the topic and understand (and to some extent share) the frustration, but I think it could have been said a bit nicer. I’m sure there was no bad intent behind the OP’s posting.
7 Likes
Yes, that’s the problem here. If you want to use AI, you have to do the extra work of carefully checking everything it does. If you use AI without checking and then ask other people to check or fix it for you, you are just wasting their time.
When we do code reviews, one of the goals is to help the person submitting code understand how they can improve, and then the nexttime they submit something, there are less changes to make, and eventually that person gets commit access to Haiku because there is no need to review their code anymore.
If the submission is generated with AI, we can’t get the AI to learn anything from the review comments. And so we are stuck doing the same comments over and over again. In that case it is quicker to write the code or documentation ourselves.
3 Likes
If you use great prompting techniques and good example input, the AI doesn’t need any improvements. The current AI’s are generative, so they’re not just some glorified search engine anymore. But as always: garbage in, garbage out. If your output is crap, you need to use a better prompt.
I don’t care about your prompting, I just said if you want to use an AI, it’s up to you to check what it did. Do not outsource the checking work (which is the most difficult part) to someone else.
Generative AI is a fancy way to say “it will make stuff up”. Which is not what we want when writing documentation about existing APIs, right? So, yes, if your preferred way of working is asking an AI “tell me how this works”, getting wrong results, then telling the AI “hey you stupid, thatws not how it works!” until eventually you get something that’s correct (aka “great prompting technique”), sure, fine. Personally I think I will be faster at writing documentation by reading the code myself and checking what it does, instead of asking an AI to guess what it does and checking if it guessed right.
3 Likes
Until recently I was very sceptical as well, until I followed a training and saw some results. The ‘making stuff up’ part is really undervaluing the strength of the current AI I think. With good examples and directions, it can be a valuable tool.
Point is not whether AI is useful or not. It may be very useful for some type of task, but it is mismatched with HUMAN reviewer collaboration.
Good reviewers often have better skill than contributor when they contribute at that time, then why they welcomes contribution? It is because they are time constrained.
Reviewing contribution is also time consuming process until the reviewee got idea to do things correct way and reviewers have consensus with contributor.
Honestly often reviewers spend more time than they do that task theirselves. But they invest time with expectation contributor will do better next time as PulkoMandy said.
AI’s memory and learning model from past input doesn’t fit to this expectation.
(Yes we are off-topic now.)
1 Like
I’ve got the Haiku HTML Book generated via doxygen, however I’ve noticed the below error :
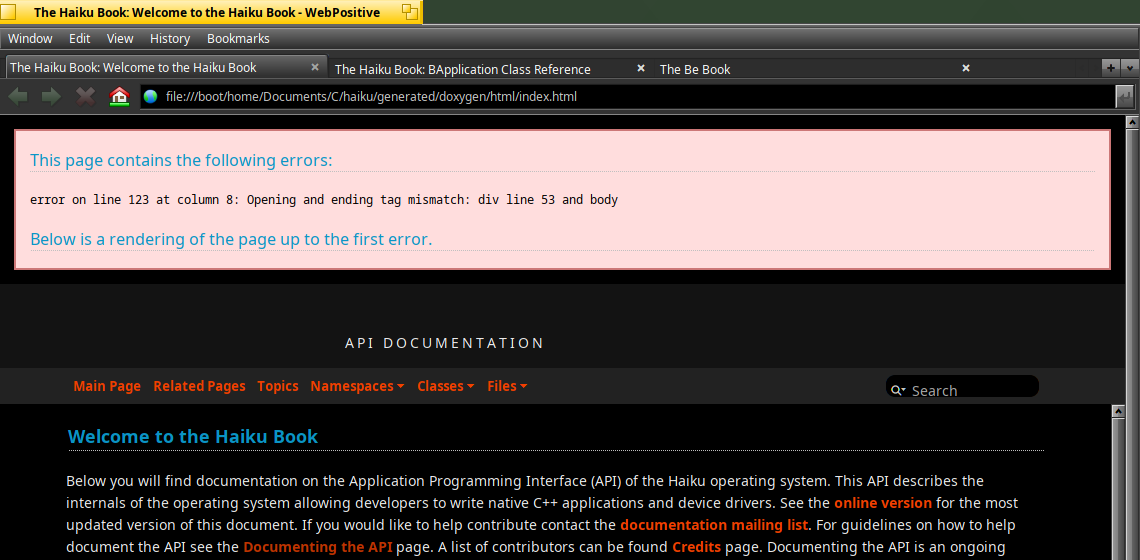
Anyone noticed it also ?
The fixing of this issue is very simple in the HTML, because there’s missing “div” corresponding to “div class=contents”
However the fix for Doxygen is less trivial : anyone has some pointer where it could be necessary to fix that ?
What is really strange is that behavior depends on the browser :
Falkon : no error + white theme + logo display OK
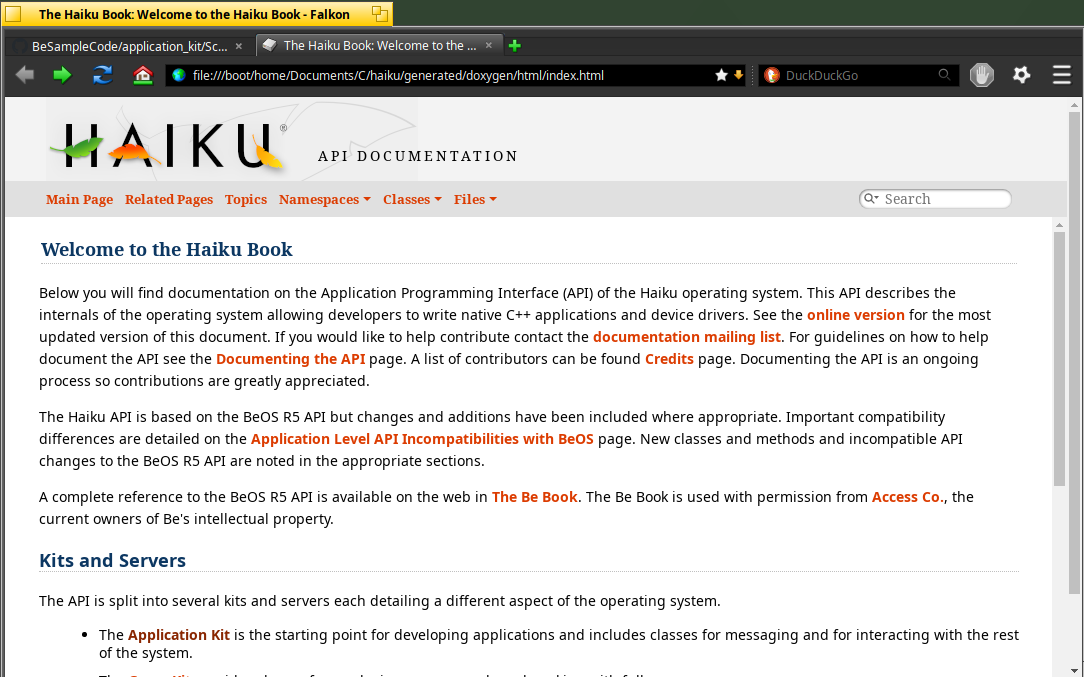
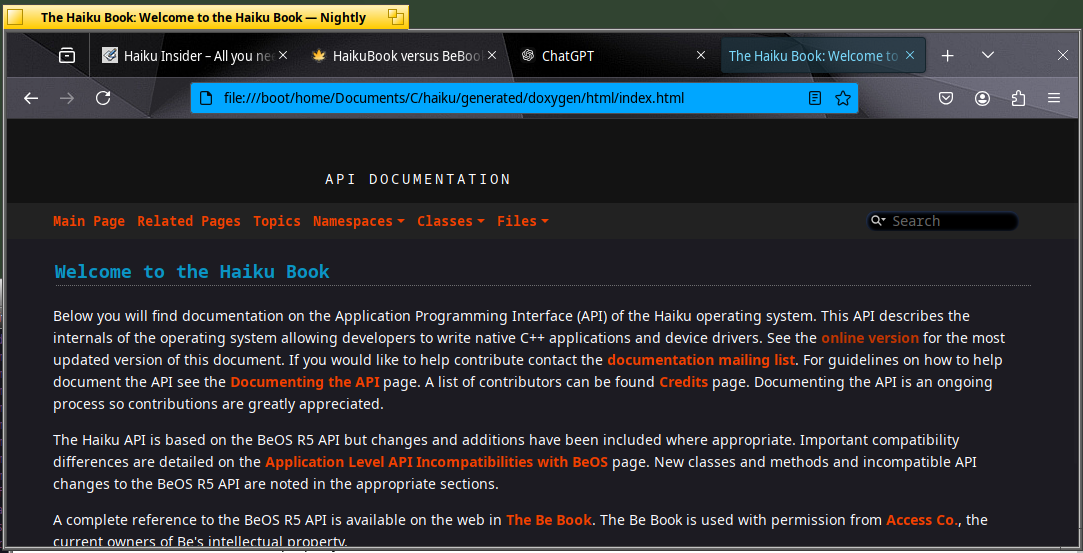
Firefox : no error + black theme + logo display not OK
And the reference page on the website is not having the “div id=doc-content” which I suspect is leading to the error in WebPostive :
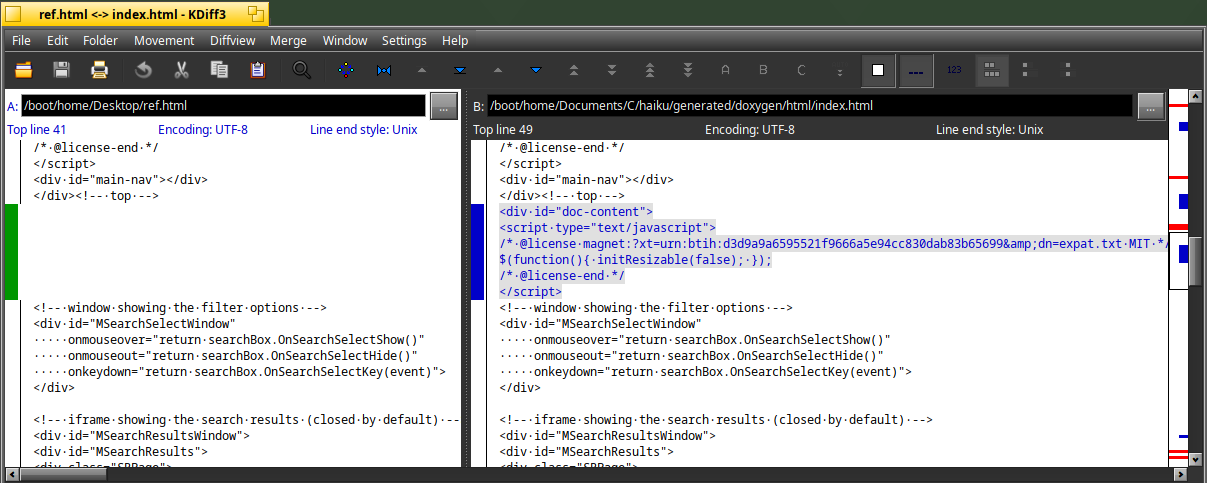
Very strange…
Browser should not show an error when closing tag is missed: What happens if we don't add a closing tag? - #18 by dev6190329401 - HTML FAQ - Codecademy Forums .
What doctype does that html page have, if any?
The doctype is consistent with the same page on the website, so nothing weird there.
What I have discovered so far is that when putting a minimal Doxyfile, the issue is resolved, so I guess it’s due to some bad “.html” customized files.
I will start instead from a standard Doxyfile to have something clean to start with.
The MIME sniffer decided that the file is xhtml instead of html. As a result, WebPositive parses it as xhtml, where:
- Not closing a tag is an error
- Errors are fatal and stop processing
Other browsers do not rely on the MIME sniffer and apparently do a better job at finding the right file type.
I’m confused by this. Why would it? The html engine should already know what type it is upon reading the very first tag. They are substantially different between xhtml and html
Yep. It’s due to a change in the template between the version we had with the beta release and the current one.
For the structure, you just have to add the closing div to the footer, like in Doxygen proper. But someone should also check the header, if styles are affected, the configuration file, and whether we really still need all that nowadays.
Long time since I knew these details, but I think it is indeed the kind where you have to close your tags:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Yes, that is the strict one. So it seems webpositive is behaving properly here
The first tag is always <html> in all html and xhtml versions. And the DOCTYPE is also “html”, so you have to parse quite deep down into the xml namespaces or dtd to decide what it really is.
Which is unfortunate, because parsing html and parsing xml require quite different parser logic and it’s not desirable to start parsing, notice that you made the wrong choice, and start over. To avoid that, the browaser uses the server provided MIME type if available. In the case of Haiku, it also does that for local files if the MIME attribute is available.
The first tag is only html in html5. In lower versions this always starts with the doctype first iirc
Valid HTML5 still starts with a Doctype,but it’s much simpler than the older ones:
<!DOCTYPE html>
<html>
...
It usually also works without the doctype tag,but Validators will tell you that it’s better to have it.