Well, we are not Debian so one could still detect some flaws ![]() Could very well be the files are more the problem then mupdf, or mupdf should be fixed (I wouldn’t know how to).
Could very well be the files are more the problem then mupdf, or mupdf should be fixed (I wouldn’t know how to).
DocumentViewer itself worked out for me, maybe you could share a link to one of those failing ones so others could check there too?
OK, seems @waddlesplash already merged the changes, little sidenote when I applied the patch in a recipe where I got some output from haikuporter/git.
Applying patch "/Share/haikuports/haiku-apps/documentviewer/patches/45.patch" ...
/Share/haikuports/haiku-apps/documentviewer/patches/45.patch:97: space before tab in indent.
uint32 index = 0;
/Share/haikuports/haiku-apps/documentviewer/patches/45.patch:371: space before tab in indent.
uint32 const& height, int const& rotation = 0) = 0;
/Share/haikuports/haiku-apps/documentviewer/patches/45.patch:498: space before tab in indent.
virtual std::unique_ptr<BBitmap> RenderBitmap(int const& pageNumber,uint32 const& width,
/Share/haikuports/haiku-apps/documentviewer/patches/45.patch:499: space before tab in indent.
uint32 const& height, int const& rotation = 0);
/Share/haikuports/haiku-apps/documentviewer/patches/45.patch:569: space before tab in indent.
virtual std::unique_ptr<BBitmap> RenderBitmap(int const& pageNumber,uint32 const& width,
warning: squelched 1 whitespace error
warning: 6 lines add whitespace errors.
Please open an issue about this at the DocumentViewer GitHub repo and make sure you attach 1 or 2 of the PDF files that cause the problem.
The whitespace situation (tabs vs. spaces, sometimes both) was pretty messy when I first touched the DocumentViewer code, there was a warning about misleading indentation, which I fixed (at least g++ is happy with the code now). haikuporter seems to be bit more picky, so it is entirely possible that my changes introduced some more whitespace problems while fixing others.
I’ll drop by on IRC later in the day, maybe we can sort this out quickly.
1 Like
I’m not the developer here, can only report. ![]()
Sorry, I am late to the conversation.
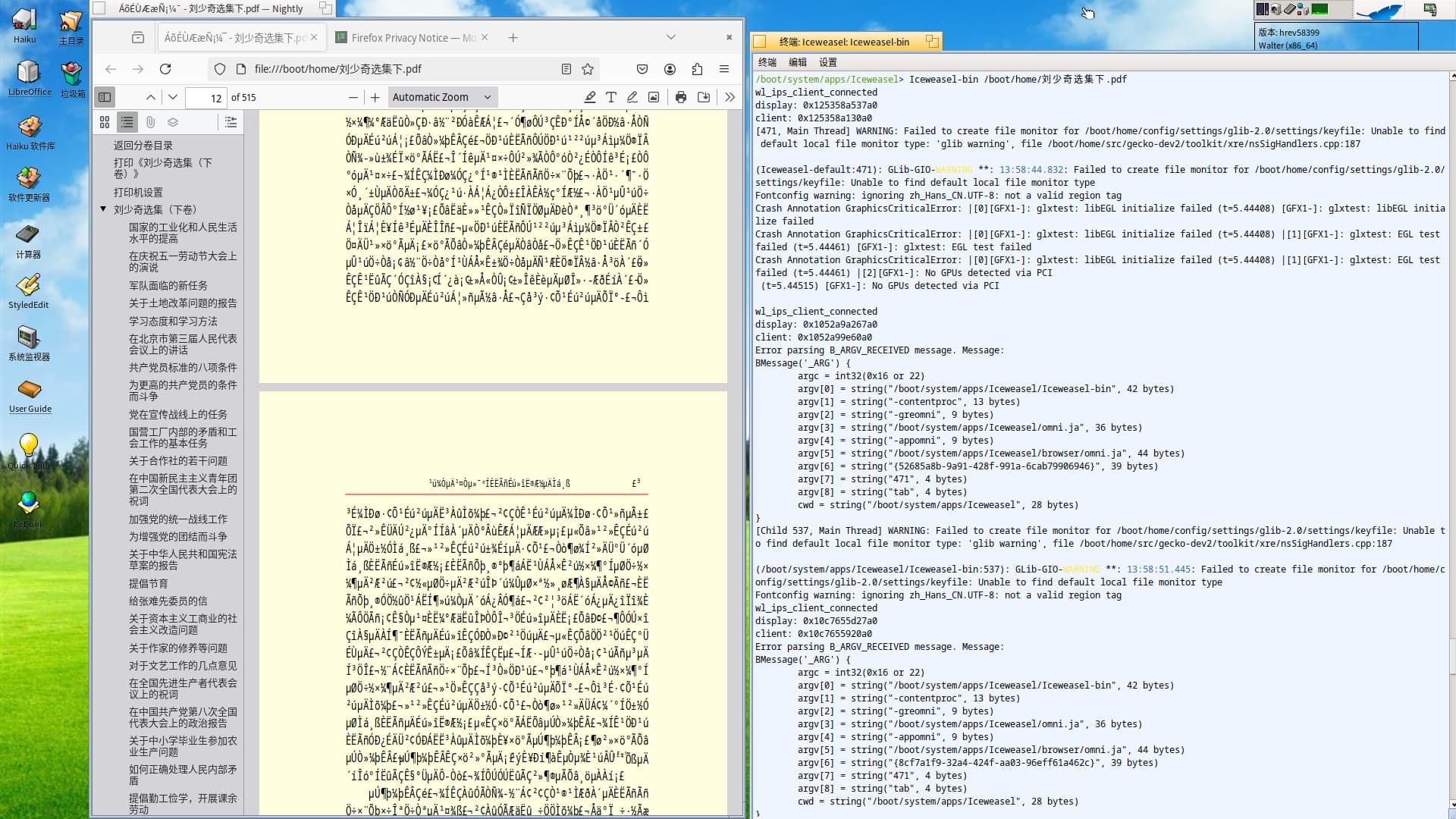
The wrong look of the document looks for me as encoding problem. Exactly the same looks Russian documents in wrong encoding. More detailed:
- There exist encoding of document and encodings of fonts. If they mismatch, this leads to unreadable render;
- There exist one-byte (e.g. UTF-8) and multi-byte encodings (e.g. UTF-16-LE). If multi-byte encoding is interpreted as one-byte or vice-versa, this leads to unreadable render;
- CJK languages prefer their own multi-byte encodings (e.g. BIG5). If BIG5 text is interpreted as encoded otherwise (e.g. UTF-16-LE), this leads to unreadable render.
Note: An encoding is the way each graphic sign (glyph) is associated with a number (e.g. ‘W’ → 0x57 = 87) and then the way this number is presented in document (e.g. UNICODE → UTF-8, UNICODE → UTF-16-LE, etc).
The problem with encoding can be debugged to some extent with:
FontForge- a free application that can inspect the font encoding (and encodings supported by font), and modify this encoding,iconvtool can be used to re-encode the text from one encoding to another. Unfortunately, only plain text files can be converted, so no .DOCX / .ODT / .PDF / etc.
EDIT: The problem I see in images looks like a multi-byte encoding is interpreted as one-byte one. For example, Russian letter ‘Ж’ in UNICODE has the number 0x0416, which is more than one byte can hold (maximum 0xFF), but it can be presented as sequence of bytes, the simplest one is the encoding UTF-16-LE: 0x0416 → 0x04, 0x16. But this sequence of 2 bytes if interpreted as one-byte encoding (e.g. ISO-8859-1) is understood as 2 characters: 0x04 = EOT = Ctrl+D followed by 0x16 = SYN, both unprintable characters, which may be presented differently. Similarly, all Russian alphabet is presented in UNICODE in range 0x0410…0x044F. Because the first byte of all them is the same 0x04, when interpreted as ISO-8859-1, each letter is presented by 2 glyphs, first being 0x04 = EOT = Ctrl+D.
EDIT2: The plain test can be copied from some other document format (.DOCX, .ODT, .PDF) by selecting the text, copying it to the clipboard and pasting in some empty text document e.g. in StyleEdit.
I see also that the error log from the 2nd screenshot of the original post says about font substitution, and uses Courier font for rendering. For sure Courier font does not cover Chinese glyphs. The right font for properly displaying is the one with support for CJK languages, e.g. default Haiku Noto AFAIK.