I pushed current WIP code there: Commits · Milek7/haiku-work · GitHub
I did not reuse much existing code from efi loader or that linked github earlier, but that’s just because I needed some practice with how it all works, we will need to decide later which approach use for upstreaming.
If you want to try it on different device it needs updating kernel debug serial in arch_debug_console.cpp, currently it’s hardcoded there to pl011@0x9000000. (and likely add appropiate device memory mapping in efi loader, in kernel address space)
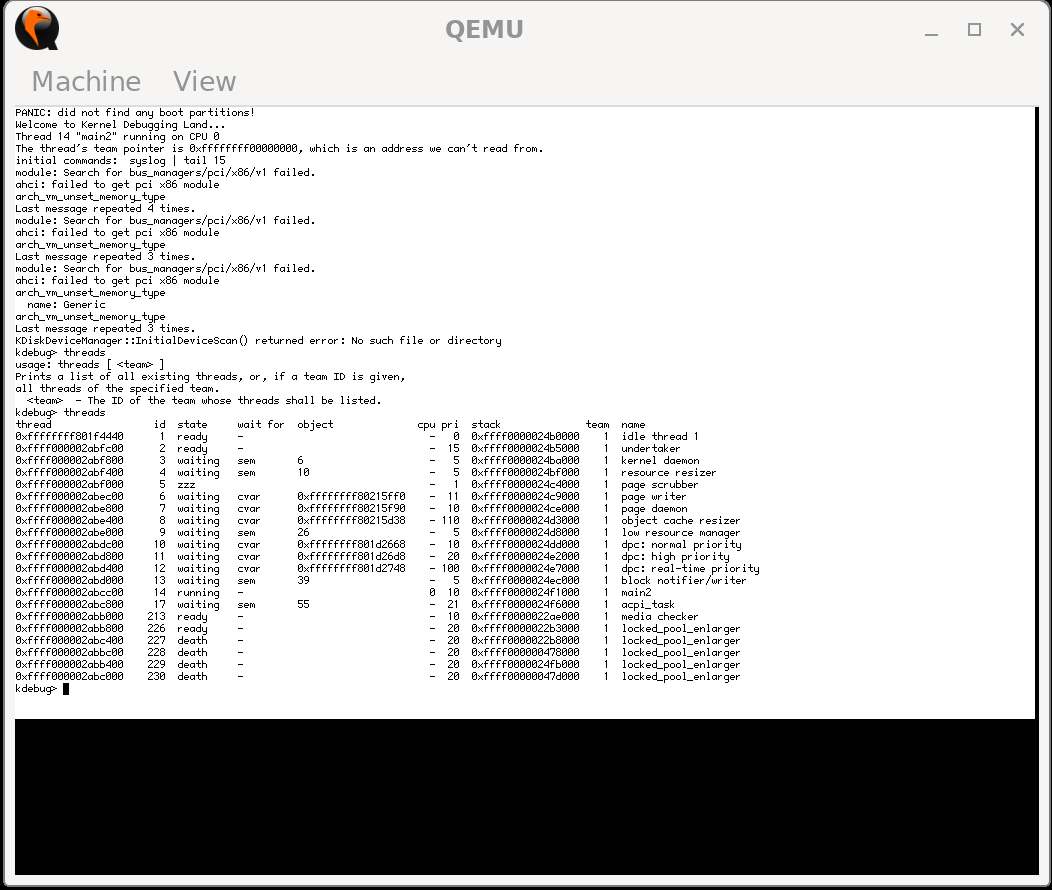
In qemu it runs all the way up to PANIC: did not find any boot partitions!, but hardware is less forgiving so I would expect some snags there
No. Drivers ask PCI MSI interrupts module that is currently declared as “x86-specific”, but actually it isn’t. MSI interrupt handling is a part of PCI Express specification and available on all hardware that support it including RISC-V and ARM.
I’ll be incorporating other parts for the next commit on properly dealing with an ongoing MMU in EL1 in EFI.
Let me remark that:
Will fail, as that position is not covered by the MMU, I see in your next commit that you opened the whole kernel virtual range, avoiding the commented fail. Can you explain?
64 bit Haiku kernels (x86_64, riscv64) use linear mapping of whole RAM for easy and efficient access to physical memory. So physical RAM addresses can be converted to virtual by adding some fixed offset value.
Why? This is stack top, so only memory below this address should be used. - 8 seems wrong, AAPCS64 ABI requires that stack is 16-byte aligned, and it will probably fault on hardware when SCTLR_EL1.SA bit is set. - 16 would be fine but I don’t see reason for subtracting here.
This is linear mapping that is used by PhysicalPageMapper to access memory directly. (instead of mapping it in-and-out which is necessary on 32-bit platforms, when there isn’t enough virtual address space to cover all memory). Note that mapping everything like that works fine only for qemu, for hardware we also want this linear mapping but it needs to be changed to map only areas covering physical RAM (otherwise speculative access might cause unwanted MMIO reads or bus SError).
This was the mapping for the kernel Stack, this involves MMU covers from 0xffff000002000000 to 0xFFFF00000200FFFF.
Writting 0xFFFF000002010000(top+size) to the stack registers provoked an exeception, because that address is already in the next page (not covered by MMU). That is the reason of the substraction.
Alright… hybrid kernels. Maybe is not feasible but I would delay that as much as possible in the progress of the port, to catch as soon a possible unintented acceses & bugs.
Understood, Indeed that mappìng won’t work for me (at physical 0x0 is the mappping of the xSPI controller)
I didn’t push the code yet because it’s too hardcoded.
I’m having trouble with PCI controller discovery because it seems pci_controller_init is getting called at the beginning, but I need information from acpi/devicetree which is only parsed later.
x86 code parses acpi MCFG manually, but that’s not enough here because while it contains config space address, I/O ranges information are accessed through PNP0A03 _CRS method, thus it requires fully parsed acpi namespace.
riscv uses devicetree and binds root module in proper place by filtering in pci_root_supports_device, but I’m not sure how it resolves the problem that by the point this device is discovered pci_controller_init was already called earlier.
If I remember correctly PCI module loading fails if FDT node is not found (not yest registered etc.). So PCI module will be functional if accessed after publishing FDT bus nodes. If it is accessed before, it will load, fail and unload, potentially multiple times.
I think that PCI initialization should be reworked to have initially empty bus with no host controllers and then dynamically register PCI host controllers during ACPI/FDT bus enumeration. Hot pluggable PCI devices also exist.
I think it would make sense to rewrite how ACPI is initialised, it is a bigger task though. ACPI spec expects it to be done very early as well, but we do it quite late in boot.
I’m working on this for my (x86_64, boring) laptop.
It is not possible to have the PCI module depend on the ACPI module at the kernel level because the ACPI module depends on the PCI one currently. So the kernel complains about a circular dependency.
What I did so far:
Change the support_device function so that the PCI root supports the ACPI PNP0A03 device node, instead of the “root” device node. This is similar to what is done for FDT for RISC-V.
What I did not do yet:
In the device initialization, load the ACPI module, use it to call the _CRS method, and parse the result.
I will submit my patch to Gerrit in a few hours when I’m back home.
Is RPI4 build able to print anything on uart? I have build Haiku ARM for rpi4. Here’s what happens.
Once I use the dd command to burn haiku-rpi4.mmc to the sd card, SD is not being able to mount again after the dd command. I get following error when I try to mount the sd card:
mount: /mnt: wrong fs type, bad option, bad superblock on /dev/loop0,
missing codepage or helper program, or other error.
dmesg(1) may have more information after failed mount system call.
Also, there’s no uart output with the sdcard too. Is there anything wrong that i’m doing??
I tried the arm64 port on rpi3 so far, there are still a few issues that we’re trying to iron out with @oruizdorantes
I expect the rpi4 would be a bit more difficult as /chosen/std-path seems to be missing from the device tree, so I’m not sure if the bootloader can recognize the mini-UART
but maybe we need to go back one step:
how did you prepare the SD card, what is the exact command?
how does your config.txt look like?
are you trying to boot Haiku with u-boot or TianoCore?